kafka测试方法
kafka的测试主要从功能和性能两方面出发:
- 测试系统在高负载下是否稳定,即性能测试。
- 测试系统是否能够保证生产的消息一定被消费,即正确性测试。
1. 性能测试
1.1 性能测试定义
性能测试是指通过模拟生产运行的业务压力或用户使用场景来测试系统的性能是否满足生产性能的要求。从广义来看,性能测试则是压力测试、负载测试、强度测试、容量测试、大数据量测试、基准测试等和性能相关的测试的统称。
压力测试是指通过逐步增加系统负载,测试系统性能的变化,并最终确定在什么负载条件下系统性能处于失效状态,通过确定一个系统的瓶颈或者不能接受的性能点,来获得系统能提供的最大服务级别的。压力测试的目的是
- 找出因资源不足或资源争用而导致的错误。
- 确定测试对象能够处理的最大工作量。
- 可以让测试工程师观察系统在出现故障时的反应。系统是不是保存了它出现故障时的状态?是不是它突然间崩溃掉了?它是否只是挂在那儿什么也不做了?在重启之后,它是否有能力恢复到前一个正常运行的状态?
基准测试是指在一定的软件、硬件及网络环境下,模拟一定数量的虚拟用户运行一种或多种业务,将测试结果作为基线数据,在系统调优或系统评测的过程中,通过运行相同的业务场景比较测试结果,确定调优的结果是否达到预期效果,或者为系统的选择提供决策数据。主要用于性能调优。在经过测试获得了基准测试数据后,进行环境调整(包括硬件配置、网络、操作系统、应用服务器、数据库等),再将测试结果与基准数据进行对比,判断调整是否达到最佳状态。
1.2 性能测试工具
Copy From 《极客时间-Kafka核心技术与实战-31 常见工具脚本大汇总》 + 《 Kafka 性能测试脚本详解》+ 《Kafka性能测试》
Kafka有自带的性能测试工具,可以对生产者、消费者的性能进行测试。可以参考《Kafka压力测试(自带测试脚本)(单机版)》的方法进行压力测试分析。当我们对Kafka进行改动时,也可以按照LinkedIn提供的《Kafka benchmark》脚本来运行一下,看看运行结果是否表现更好。
1.2.1 测试生产者性能
先说测试生产者的脚本:kafka-producer-perf-test。它的参数有不少, 参数详解如下:
| 参数名 | 含义 |
|---|---|
| -h, --help | 显示使用帮助并退出 |
| --topic | 指定生产的消息发往的 topic |
| --num-records | 指定生产的消息总数 |
| --payload-delimeter | 如果通过 --payload-file 指定了从文件中获取消息内容,那么这个参数的意义是指定文件的消息分隔符,默认值为 \n,即文件的每一行视为一条消息;如果未指定 --payload-file 则此参数不生效 |
| --throughput | 限制每秒发送的最大的消息数,设为 -1 表示不限制 |
| --producer-props | 直接指定 Producer 配置,格式为 NAME=VALUE,例如 bootstrap.server=127.0.0.1:9092,通过此种方式指定的配置优先级高于 --producer.config |
| --producer-config | 指定 Producer 的配置文件,格式参照官方的 config/producer.properties |
| --print-metrics | 在测试结束后打印更详尽的指标,默认为 false |
| --transactional-id | 指定事务 ID,测试并发事务的性能时需要,只有在 --transaction-duration-ms > 0 时生效,默认值为 performance-producer-default-transactional-id |
| --transactional-duration-ms | 指定事务持续的最长时间,超过这段时间后就会调用 commitTransaction 来提交事务,只有指定了 > 0 的值才会开启事务,默认值为 0 |
| --record-size | 指定每条消息的大小,单位是字节,和 --payload-file 两个中必须指定一个,但不能同时指定 |
| --payload-file | 指定消息的来源文件,只支持 UTF-8 编码的文本文件,文件的消息分隔符通过 --payload-delimeter 指定,和 --record-size 两个中必须指定一个,但不能同时指定 |
示例如下:
$ bin/kafka-producer-perf-test.sh \
--topic test-topic \
--num-records 10000000 \
--throughput -1 \
--record-size 1024 \
--producer-props bootstrap.servers=kafka-host:port acks=-1 linger.ms=2000 compression.type=lz4
上述命令向指定主题发送了1千万条消息,每条消息大小是1KB, 并且ack=-1。该命令允许你在producer-props后面指定要设置的生产者参数,比如本例中的压缩算法、延时时间等。
输出结果的格式如下:
2175479 records sent, 435095.8 records/sec (424.90 MB/sec), 131.1 ms avg latency, 681.0 ms max latency.
4190124 records sent, 838024.8 records/sec (818.38 MB/sec), 4.4 ms avg latency, 73.0 ms max latency.
10000000 records sent, 737463.126844 records/sec (720.18 MB/sec), 31.81 ms avg latency, 681.00 ms max latency, 4 ms 50th, 126 ms 95th, 604 ms 99th, 672 ms 99.9th.
它会打印出测试生产者的吞吐量(MB/s)、消息发送延时以及各种分位数下的延时。一般情况下,消息延时不是一个简单的数字,而是一组分布。或者说,我们应该关心延时的概率分布情况,仅仅知道一个平均值是没有意义的。这就是这里计算分位数的原因。通常我们关注到99th分位就可以了。比如在上面的输出中,99th值是604ms,这表明测试生产者生产的消息中,有99%消息的延时都在604ms以内。你完全可以把这个数据当作这个生产者对外承诺的SLA。
1.2.2 测试消费者性能
测试消费者也是类似的原理,只不过我们使用的是kafka-consumer-perf-test脚本,参数如下:
| 参数名 | 含义 |
|---|---|
| --bootstrap-server | 指定 broker 地址,必选,除非用 --broker-list 代替(不建议) |
| --topic | 指定消费的 topic,必选 |
| --version | 输出 Kafka 版本 |
| --consumer.config | 指定 Consumer 配置文件 |
| --date-format | 指定用于格式化 *.time 的规则,默认为 yyyy-MM-dd HH:mm:ss:SSS |
| --fetch-size | 指定一次请求消费的大小,默认为 1048576 即 1 MB |
| --from-latest | 如果 Consumer 没有已经建立的 offset,则指定从 log 中最新的位点开始消费,而不是从最早的位点开始消费 |
| --group | 指定 ConsumerGroup ID,默认为 perf-consumer-40924 |
| --help | 显示使用帮助并退出 |
| --hide-header | 指定后不输出 header 信息 |
| --messages | 指定消费的消息数量,必选 |
| --num-fetch-threads | 指定 fetcher 线程的数量 |
| --print-metrics | 指定打印 metrics 信息 |
| --reporting-interval | 指定打印进度信息的时间间隔,默认为 5000 即 5 秒 |
| --show-detailed-stats | 指定每隔一段时间(由 --reporting-interval 指定)输出显示详细的状态信息 |
| --socket-buffer-size | 指定 TCP 的 RECV 大小,默认为 2097152 即 2 MB |
| --threads | 指定消费的线程数,默认为 10 |
| --timeout | 指定允许的最大超时时间,即每条消息返回的最大时间间隔,默认为 10000 即 10 秒 |
示例如下:
$ bin/kafka-consumer-perf-test.sh \
--broker-list kafka-host:port \
--messages 10000000 \
--topic test-topic \
从指定消息消费1千万条消息(一定要先生产再消费,否则会报错)
输出结果的格式如下:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2019-06-26 15:24:18:138, 2019-06-26 15:24:23:805, 9765.6202, 1723.2434, 10000000, 1764602.0822, 16, 5651, 1728.1225, 1769598.3012
有点令人遗憾的是,输出结果没有计算不同分位数下的分布情况。因此,在实际使用过程中,这个脚本的使用率要比生产者性能测试脚本的使用率低。
输出解释:
| 输出项 | 含义 |
|---|---|
| start.time | 消费开始的时间,格式由 --date-format 指定 |
| end.time | 消费结束的时间,格式由 --date-format 指定 |
| data.consumed.in.MB | 消费到的数据总大小,单位为 MB |
| MB.sec | 消费 TPS,即每秒消费的消息大小 |
| data.consumed.in.nMsg | 消费到的总消息数 |
| nMsg.sec | 消费 TPS,即每秒消费的消息条数 |
| rebalance.time.ms | 消费者组重平衡的耗时,单位为 ms,0 表示没有发生重平衡 |
| fetch.time.ms | fetch 线程的总耗时,单位为 ms |
| fetch.MB.sec | fetch 线程每秒钟获取到的消息大小 |
| fetch.nMsg.sec | fetch 线程每秒钟获取到的消息数量 |
1.2.3 端到端延迟测试
端到端延迟是消息生成到消费之间的时间。 这对于实时应用程序尤其重要。
例如,如果我们看一下 kafka-consumer-perf-test.sh 脚本的内容,将会看到对 kafka-run-class.sh 脚本的调用,并以 kafka.tools.ConsumerPerformance类 作为参数。那我们以kafka.tools.EndToEndLatency 作为参数,可以得到端到端计算时间延迟.
例如,在我们的test-topic测试主题中,要生成和使用大小为1kb的消息共1万条,并且将acks值设置为1(leader acks)并通过ssl端口9092进行加密数据传输,我们的命令如下:
$ bin/kafka-run-class.sh kafka.tools.EndToEndLatency 127.0.0.1:9092 test-rep-one 10000 1 1024
结果如下:
0 24.462583
1000 4.121916000000001
2000 0.210125
3000 0.175917
4000 0.23775
5000 0.1855
6000 0.281
7000 0.126708
8000 0.168417
9000 0.441625
Avg latency: 0.3095 ms
Percentiles: 50th = 0, 99th = 1, 99.9th = 5
2. 正确性测试
2.1 正确性测试常用方法
Copy From 《Jepsen 的使用与线性一致性》
对于分布式系统来说,正确性是最重要的特性,而正确性是很难证明的,尤其是分布式系统的正确性。所以我们对于分布式系统的测试往往从形式化验证和软件工程的测试方法:
2.1.1 形式化验证
对于分布式系统的算法模型,需要进行形式化验证,利用数学语言证明算法满足正确性。目前比较常用的是TLA+,TLA+是图灵奖得主Leslie Lamport发明的专门用来描述并验证复杂系统行为的形式化方法,使用TLA+可以帮助我们在设计时,基于系统层面的抽象对系统的正确性做形式化、规范的描述,并且定义出设计的正确性属性,自动化地加以验证,以正确性为驱动进行系统建模和设计。
TLA+验证需要开发者拥有大量的形式化方法理论知识。
2.1.2 工业化测试(混沌工程)
而在实际的生产环境里,多节点,交互复杂的分布式系统中,节点异常,网络异常,配置变更等场景不常发生但不可避免。为了应对这些可能出现的场景,我们对系统的测试必须尽可能提高这些事件发生的概率,比如Leadership changes, Partial network outage,从而测试整个系统的正确性。所以常见的做法如下:
- 让系统的某些参数设置的不合理, 但是不违反正确性, 这样可以让那些极端的场景下的问题暴露出来。比如Election timeout 设置成非常低, Heartbeat 的间隔非常高 这样就导致更频繁的Leader Changes. 更频繁的快照等等这些操作.
- 让运行的环境出现频繁的外部环境变化, 比如频繁进程随意启停, 网络丢包, 断网, 频繁Membership change 等等
- 长时间的压力测试运行,引入稳定性压力测试和极限负载情况下导致系统崩溃的破坏性压力测试。
而在错误注入这个方向,Jepsen是一个很强有力的工具。 Jepsen目前被认为是工程领域在一致性验证方面的最佳实践
2.2 jepsen基本概念
Copy From 《Jepsen 测试框架在图数据库 Nebula Graph 中的实践》
2.2.1 jepsen整体架构
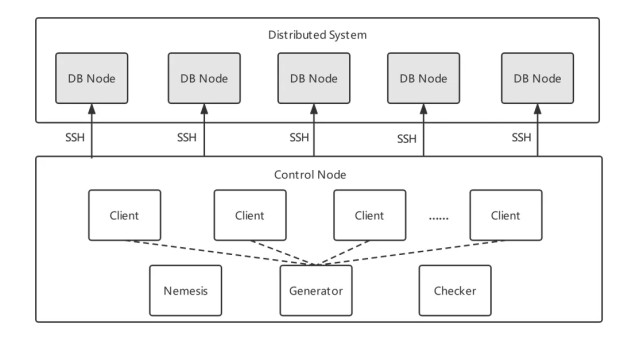
Jepsen 测试推荐使用 Docker 搭建集群。默认情况下由 6 个 container 组成,其中一个是控制节点(Control Node),另外 5 个是数据库的节点DB Node(默认为 n1-n5)。控制节点在测试程序开始后会启用多个 worker 进程,并发地通过 SSH 登入数据库节点进行读写操作。
测试开始后,控制节点会创建一组进程,进程包含了待测试分布式系统的客户端Client。另一个 Generator 进程产生每个客户端执行的操作,并将操作应用于待测试的分布式系统。每个操作的开始和结束以及操作结果记录在历史记录中。同时,一个特殊进程 Nemesis 将故障引入系统。
测试结束后,Checker 分析历史记录是否正确,是否符合一致性。用户可以使用 Jepsen 的 knossos 中提供的验证模型,也可以自己定义符合需求的模型对测试结果进行验证。同时,还可以在测试中注入错误对集群进行干扰测试。
最后根据本次测试所规定的验证模型对结果进行分析。
2.2.2 如何使用 Jepsen
使用 Jepsen 过程中可能会遇到一些问题,可以参考一下使用 Tips:
- 在 Jepsen 框架中,用户需要在 DB 接口中对自己的数据库定义下载,安装,启动与终止操作。在终止后,可以将 log 文件清除,同时也可以指定 log 的存储位置,Jepsen 会将其拷贝至 Jepsen 的 log 文件夹中,以便连同 Jepsen 自身的 log 进行分析。
- 用户还需要提供访问自己数据库的客户端,这个客户端可以是你用 Clojure 实现的,比如 etcd 的verschlimmbesserung,或者kafka的 khdegraaf,也可以是 JDBC,等等。然后需要定义 Client 接口,告诉 Jepsen 如何对你的数据库进行操作。
- 在 Checker 中,你可以选择需要的测试模型,比如,性能测试(checker/perf)将会生成 latency 和整个测试过程的图表,时间轴(timeline/html)会生成一个记录着所有操作时间轴的 html 页面。
- 另外一个不可或缺的组件就是在 nemesis 中注入想要测试的错误了。网络分区(nemesis/partition-random-halves)和杀掉数据节点(kill-node)是比较常见的注入错误。
- 在 Generator 中,用户可以告知 worker 进程需要生成哪些操作,每一次操作的时间间隔,每一次错误注入的时间间隔等等。
2.2.3 常见错误类型
- kill-node :Jepsen 的控制节点会在整个测试过程中,多次随机 kill 某一节点中的数据库服务而使服务停止。此时集群中就少了一个节点。然后在一定时间后再将该节点的数据库服务启动,使之重新加入集群。
- partition-random-node和partition-random-halves故障是模拟常见的对称网络分区。
- kill-random-processes和crash-random-nodes故障是模拟进程崩溃,节点崩溃的情况。
- hammer-time故障是模拟一些慢节点的情况,比如发生Full GC、OOM等。
- bridge和partition-majorities-ring模拟比较极端的非对称网络分区。

2.2.4 校验模型
通过下面的场景校验模型可以验证操作历史是否正确。
- noop: nothing
- queue:Every dequeue must come from somewhere. Validates queue operations by assuming every non-failing enqueue succeeded, and only OK dequeues succeeded, then reducing the model with that history. Every subhistory of every queue should obey this property. Should probably be used with an unordered queue model, because we don’t look for alternate orderings.
- total-queue:What goes in must come out. Verifies that every successful enqueue has a successful dequeue. Queues only obey this property if the history includes draining them completely.(set:Given a set of :add operations followed by a final :read, verifies that every successfully added element is present in the read, and that the read contains only elements for which an add was attempted.(queue只要求每次dequeue操作时的元素必须已经enqueue;而total-queue在此基础上还要求所有的enqueue的元素最终全部出去)
- check-safe
- linearizable:Validates linearizability with Knossos. Defaults to the competition checker, but can be controlled by passing either :linear or :wgl.
- linearizable-register: Common generators and checkers for linearizability over a set of independent registers. Clients should understand three functions, for writing a value, reading a value, and compare-and-setting a value from v to v’. Reads receive nil, and replace it with the value actually read.
- ......
2.3 Jepsen测试message
Copy Fom 《当 Messaging 遇上 Jepsen》
首先依旧需要明确MQ在故障下需要满足怎样的一致性。Jepsen为分布式系统提供了total-queue的测试,total-queue测试需要系统满足入队的数据必须出队,也就是消息的传输必须满足at-least-once。这符合我们对RocketMQ在故障下正确性要求,因此采用total-queue对RocketMQ进行Jepsen测试。
total-queue测试如下图所示,主要分为两个阶段。第一阶段客户端进程并发地向集群随机调用入队和出队操作,入队和出队操作比例各占一半,中间会注入故障。第二阶段,为了保证每一个数据都出队,客户端进程调用drain操作,抽干队列。
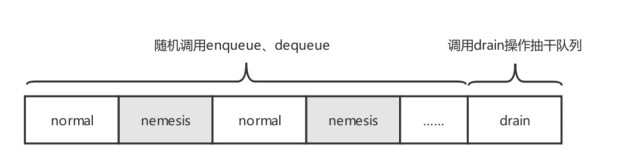
Jepsen测试提供的模型还无法完全覆盖到特定领域。比如在分布式消息领域,Jepsen仅提供了queue和total-queue的测试,来验证消息系统在故障下是否会出现消息丢失,消息重复。但是对于分布式消息队列重要的分区顺序性、全局顺序性、重平衡算法的有效性并未覆盖到。
参考文章
极客时间-Kafka核心技术与实战-31 常见工具脚本大汇总
[Jepsen 测试框架在图数据库 Nebula Graph 中的实践](