Kafka高水位机制

Kafka通过分区和备份来保证系统的高性能和高可靠。但是如何实现复制?从哪里开始复制?消费消息时如何确保数据已经备份多份?如何保证备份数据的一致性呢?这需要一整套机制来实现,比如失败重试、截断等,而hw就是其中一个关键因素。通过hw的学习可以将整个流程串一遍。
副本HW&LEO
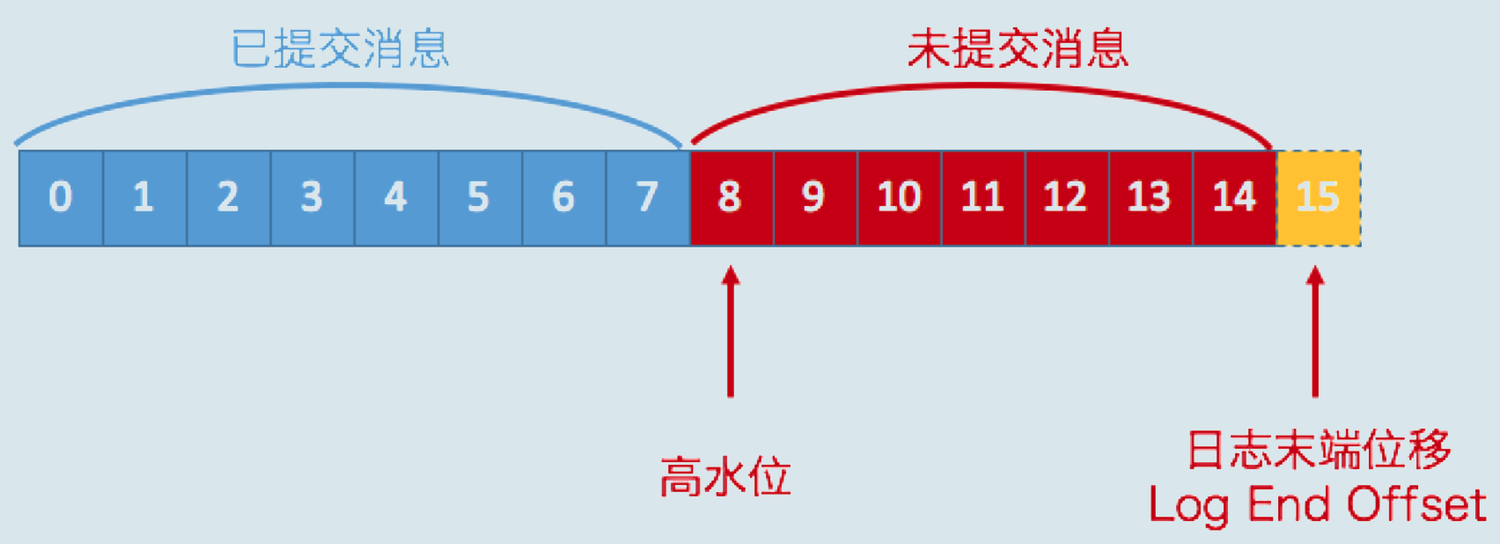
高水位和LEO是副本对象的两个重要属性:
- **LEO(log end offset) **,即日志末端偏移,指向了副本日志中下一条消息的位移值(即下一条消息的写入位置)。Follower副本LEO值落后于Leader副本LEO值的时间超过Broker端参数replica.lag.time.max.ms时,从ISR中移除。
- HW(high watermark),即已同步消息标识,因其类似于木桶效应中短板决定水位高度,故取名高水位线。在分区高水位以下的消息被认为是已提交消息,反之就是未提交消息。消费者只能消费已提交消息。(相当于确保数据成功备份多份,保证消费数据安全)
接下来,看看LEO和高水位在Broker中是如何管理的呢?
在一个分区中,Leader副本所在的节点会记录所有的副本的LEO,而Follower副本所在的节点只会记录自身的LEO。而对HW而言,各个副本所在节点都只会记录它自身的HW。leader副本收到follower副本的fetchRequest请求之后,它首先会从自己的日志文件中读取数据,然后在返回给Follower副本数居前先更新follower远程副本的LEO。

通过ReplicaManager来管理这些副本:
//-----------------------------------------------------------------------------
//ReplicaManager.scala
// ReplicaManager管理所有分区
private val allPartitions = new Pool[TopicPartition, Partition](valueFactory = Some(tp =>
new Partition(tp.topic, tp.partition, time, this)))
//-----------------------------------------------------------------------------
// Partition.scala
// Partition分区包含其所有副本信息和ISR副本信息
// hw与assignedReplicaMap有关
private val assignedReplicaMap = new Pool[Int, Replica]
@volatile var inSyncReplicas: Set[Replica] = Set.empty[Replica]
//-----------------------------------------------------------------------------
//Replica.scala
// Replica副本包含HW和LEO
class Replica(val brokerId: Int,
val partition: Partition,
time: Time = Time.SYSTEM,
initialHighWatermarkValue: Long = 0L,
val log: Option[Log] = None) extends Logging {
// the high watermark offset value, in non-leader replicas only its message offsets are kept
@volatile private[this] var highWatermarkMetadata = new LogOffsetMetadata(initialHighWatermarkValue)
// the log end offset value, kept in all replicas;
// for local replica it is the log's end offset, for remote replicas its value is only updated by follower fetch
@volatile private[this] var logEndOffsetMetadata = LogOffsetMetadata.UnknownOffsetMetadata
}
//-----------------------------------------------------------------------------
从代码可以看到,每个ReplicaManager实例都维护了所在Broker上保存的所有分区对象,而每个分区对象Partition下面又定义了一组副本对象Replica。通过这样的层级关系,副本管理器实现了对于分区的直接管理和对副本对象的间接管理。应该这样说,ReplicaManager通过直接操作分区对象来间接管理下属的副本对象。
截断(当前版本,无leader epoch)
hw不仅仅用来限制消费者消费。在日志同步时,hw配合截断能保证数据一致性。目前截断对场景有:
- 每次LeaderAndIsrRequest请求, Follower副本会截断到hw
- Follower副本 fetch数据时发现LEO > Leader LEO(Unclean leader election)
- Follower副本 fetch数据时发现LEO < Leader的startOffset,落后太多了
假设不会截断(或者说hw不存在),看看会发生什么?
比如:数据同步到这一步中间的时候(见下面副本同步-生产消息一节),Follower宕机,ack =-1时Leader都返回给Produce错误:
但是Follower重启之后数据不截断,数据就出现了冗余。
再比如: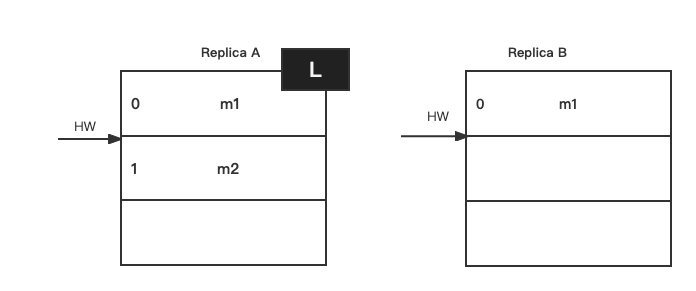
如果在上图初始状态时,A宕机了,B会被选为Leader: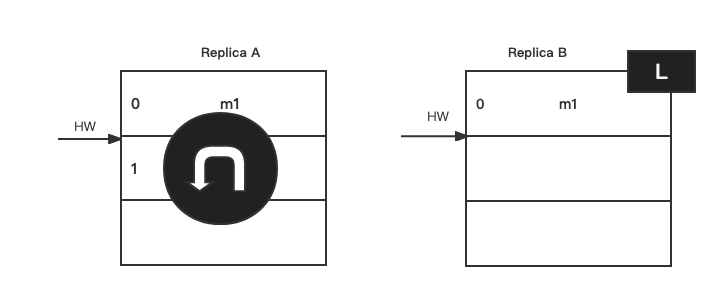
然后B新增消息之后,A重启成功,在1位置的m2和m3消息不一致了: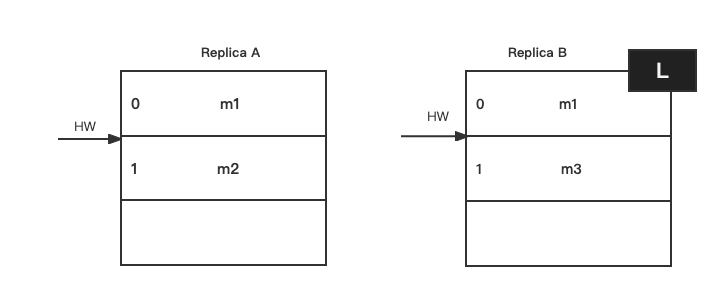
(多个Broker更是类似,如果没有配置acks=-1, 哪怕ISR Broker里面的LEO都不一定时刻一致,一旦Leader宕机,肯定会导致数据不一致)
持久化与恢复
hw持久化
hw会持久化备份在 ${log_dir}/replication-offset-checkpoint。
- 在初始化本地Replica的时候,会从持久化文件中读取hw。
- broker收到第一条LeaderAndIsrRequest请求后,启动highwatermark-checkpoint定时任务不断将hw写入本地进行持久化,待后续创建本地Replica时读取。定时周期由broker端参数 replica.high.watermark.checkpoint.interval.ms来配置。
def getOrCreateReplica(replicaId: Int = localBrokerId): Replica = {
assignedReplicaMap.getAndMaybePut(replicaId, {
if (isReplicaLocal(replicaId)) {
val config = LogConfig.fromProps(logManager.currentDefaultConfig.originals,
AdminUtils.fetchEntityConfig(zkUtils, ConfigType.Topic, topic))
val logDir = zkUtils.getReplicaLogDir(topic, partitionId, replicaId)
val log = logManager.createLog(topicPartition, config, logDir)
val checkpoint = replicaManager.highWatermarkCheckpoints(log.dir.getParentFile.getAbsolutePath)
val offsetMap = checkpoint.read
if (!offsetMap.contains(topicPartition))
info(s"No checkpointed highwatermark is found for partition $topicPartition")
val offset = math.min(offsetMap.getOrElse(topicPartition, 0L), log.logEndOffset)
new Replica(replicaId, this, time, offset, Some(log))
} else new Replica(replicaId, this, time)
})
}
/*-----------------------------------------------------------------------------
* ReplicaManager#startHighWaterMarksCheckPointThread
* 启动hw持久化定时任务
*/
def startHighWaterMarksCheckPointThread() = {
if(highWatermarkCheckPointThreadStarted.compareAndSet(false, true))
scheduler.schedule("highwatermark-checkpoint", checkpointHighWatermarks, period = config.replicaHighWatermarkCheckpointIntervalMs, unit = TimeUnit.MILLISECONDS)
}
/*-----------------------------------------------------------------------------
* ReplicaManager#checkpointHighWatermarks
* 将本地各分区副本的hw写入日志,(当由follower变为leader时读取)
*/
// Flushes the highwatermark value for all partitions to the highwatermark file
def checkpointHighWatermarks() {
val replicas = allPartitions.values.flatMap(_.getReplica(localBrokerId))
val replicasByDir = replicas.filter(_.log.isDefined).groupBy(_.log.get.dir.getParentFile.getAbsolutePath)
for ((dir, reps) <- replicasByDir) {
val hwms = reps.map(r => r.partition.topicPartition -> r.highWatermark.messageOffset).toMap
try {
highWatermarkCheckpoints(dir).write(hwms)
} catch {
case e: IOException =>
fatal("Error writing to highwatermark file: ", e)
Runtime.getRuntime.halt(1)
}
}
}
kafka checkpoint日志
kafka检查点文件Kafka的根目录下有四个检查点文件:
- replication-offset-checkpoint:对应HW,有定时任务刷写,由broker端参数 replica.high.watermark.checkpoint.interval.ms来配置
- recovery-point-offset-checkpoint:对应LEO,有定时任务刷写,由broker端参数 replica.flush。offset.checkpoint.interval.ms 来配置
- log-start-offset-checkpoint: 对应LogStartOffset,有定时任务刷写,由broker端参数 log.flush.start.offset.checkpoint.interval.ms 来配置
- cleaner-offset-checkpoint: 清理检查点文件,用来记录每个主题的每个分区已清理的偏移量。
数据库checkpoint
可以数据库故障恢复与检查点来学习checkpoint机制, 以下内容copy from 《数据库系统基础讲义》
事务对数据可进行操作时:先写运行日志;写成功后,在与数据库缓冲区进行信息交换。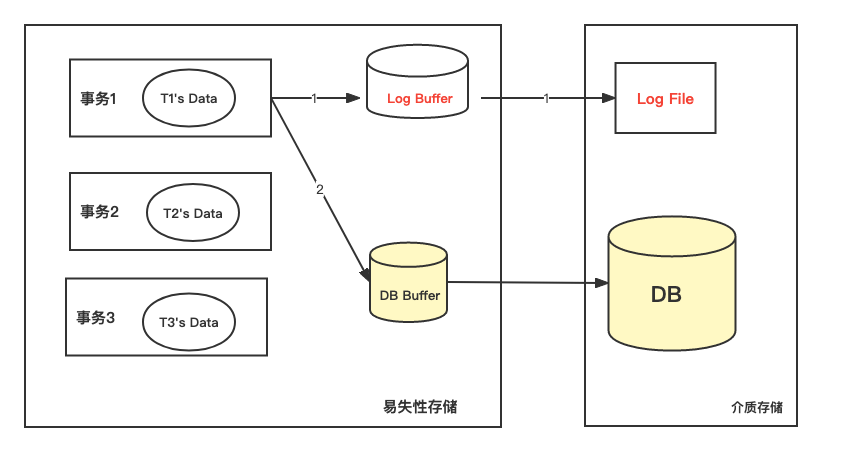
如果发生**数据库系统故障,**可通过运行日志来恢复。根据运行日志记录的事物操作顺序重做事务(当事务发生故障时已正确结束)或撤销事务(当事物在发生故障时未结束)。
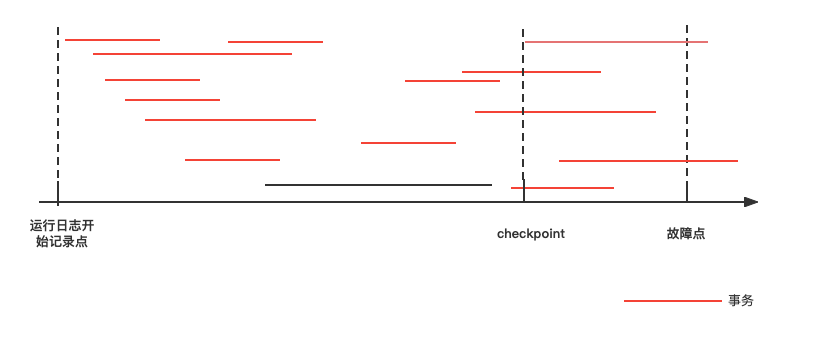
但是故障恢复是需要时间的。运行日志保存了若干天的记录,当发生系统故障时应从哪一点开始恢复呢?
DBMS在运行日志中定期的设置和更新检查点。检查点是这样的时刻:在该时刻,DBMS强制使内存DB Buffer中的内容与DB中的内容保持一致,即将DB Buffer中更新的所有内容写回DB中。即在检查点之前内存中数据与介质中数据是保持一致的。
所以系统故障的恢复:
- 检查点之前结束的事物不需要恢复(已经写入DB)
- 检查点之后结束或者正在发生的事务需要依据运行日志进行恢复(不能确定是否写回DB):故障点结束前结束的重做,故障时刻未结束的撤销。=>重做在kafka中的一种形式为:Follower根据hw截断,并重新fetch
而对介质故障对恢复通过备份实现的。在某一时刻,对数据库在其他介质存储上产生的另一份等同记录。当发生介质故障时,用副本替换被破环的数据库。由于介质恢复影响全面,在用副本恢复后还需要依据运行日志进行恢复。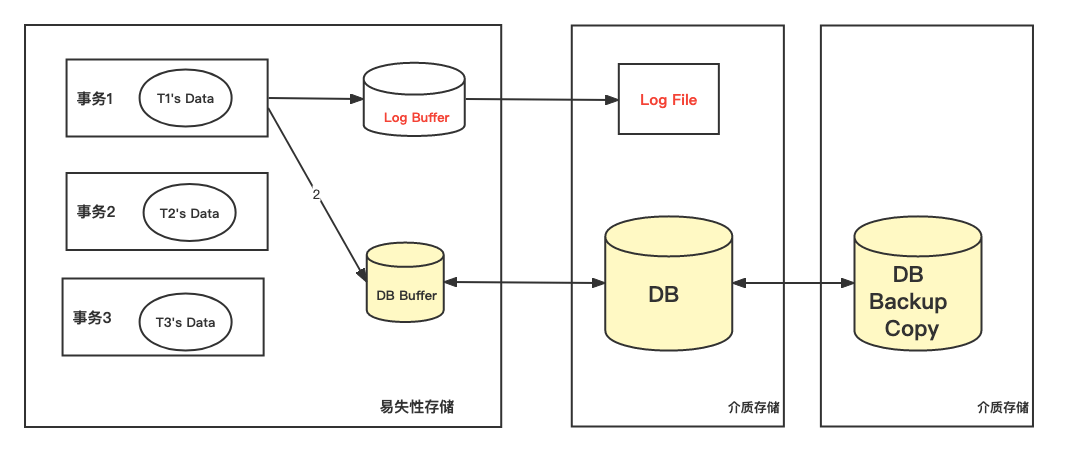
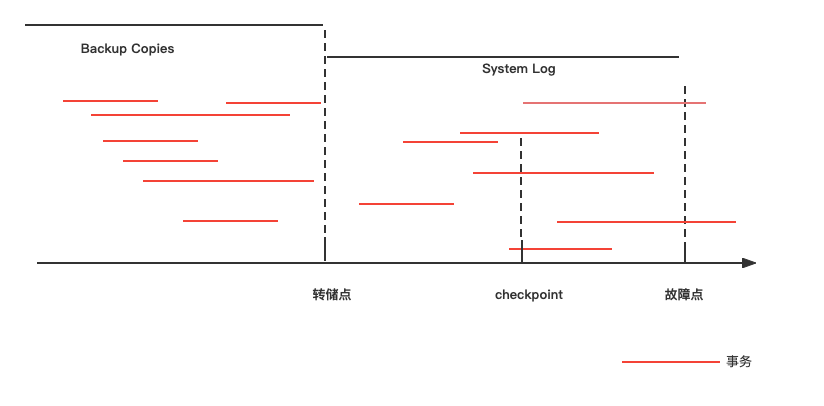
通过转储点来确定备份的时刻,转储点的设置有以下注意点:
- 备份转储周期与运行日志的大小密切相关,应注意防止衔接不畅而引起的漏洞。
- 过频,会影响系统工作效率;过疏,会造成运行日志过大,也影响系统运行性能。
思考:学习到这里的时候,我有个疑问:既然是异步持久化保存hw,那么如果在hw定时刷入checkpoint中间系统故障,重启后hw其实偏小,如果被选为leader, 数据就丢失了。所以如果系统所有broker全部在这个这段时间区间内宕机(虽说小概率),是否会导致数据丢失?
目前leader不会截断,且currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)可以保证
HW更新机制
消费消息
消费消息时,会限制到HW:
val fetchOnlyCommitted: Boolean = ! Request.isValidBrokerId(replicaId)
//对消费者消费时,maxOffset = hw
val maxOffsetOpt =
if (readOnlyCommitted)
Some(localReplica.highWatermark.messageOffset)
else
None
val fetch = log.read(offset, adjustedFetchSize, maxOffsetOpt, minOneMessage)
生产消息
Leader处理生产者请求的逻辑如下:
- 写入消息到本地磁盘。
- 更新分区高水位值。
i. 获取Leader副本所在Broker端保存的所有远程副本LEO值(LEO-1,LEO-2,……,LEO-n)。
ii. 获取Leader副本高水位值:currentHW。
iii. 更新 currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)}。
//--------------------------------------------
// Partition#appendRecordsToLeader
// 写入消息
val info = log.append(records, assignOffsets = true, log.config.leaderAppendCacheEnable)
// probably unblock some follower fetch requests since log end offset has been updated
replicaManager.tryCompleteDelayedFetch(TopicPartitionOperationKey(this.topic, this.partitionId))
// 更新高水位
(info, maybeIncrementLeaderHW(leaderReplica))
// some delayed operations may be unblocked after HW changed
if (leaderHWIncremented)
tryCompleteDelayedRequests()
info
}
//-----------------------------------------------------------------------------
//Partition#maybeIncrementLeaderHW
private def maybeIncrementLeaderHW(leaderReplica: Replica, curTime: Long = time.milliseconds): Boolean = {
val allLogEndOffsets = assignedReplicas.filter { replica =>
curTime - replica.lastCaughtUpTimeMs <= replicaManager.config.replicaLagTimeMaxMs || inSyncReplicas.contains(replica)
}.map(_.logEndOffset)
val newHighWatermark = allLogEndOffsets.min(new LogOffsetMetadata.OffsetOrdering)
val oldHighWatermark = leaderReplica.highWatermark
// Ensure that the high watermark increases monotonically. We also update the high watermark when the new
// offset metadata is on a newer segment, which occurs whenever the log is rolled to a new segment.
if (oldHighWatermark.messageOffset < newHighWatermark.messageOffset ||
(oldHighWatermark.messageOffset == newHighWatermark.messageOffset && oldHighWatermark.onOlderSegment(newHighWatermark))) {
leaderReplica.highWatermark = newHighWatermark
debug("High watermark for partition [%s,%d] updated to %s".format(topic, partitionId, newHighWatermark))
true
} else {
debug("Skipping update high watermark since Old hw %s is larger than new hw %s for partition [%s,%d]. All leo's are %s"
.format(oldHighWatermark, newHighWatermark, topic, partitionId, allLogEndOffsets.mkString(",")))
false
}
}
//-----------------------------------------------------------------------------
副本同步
Leader更新
Leader处理Follower副本拉取消息的逻辑(IO线程handleFetchRequest)如下:
- 读取磁盘(或页缓存)中的消息数据。
- 使用Follower副本发送请求中的位移值更新远程副本LEO值。
- **更新分区高水位值(**具体步骤与处理生产者请求的步骤相同)。
// if the fetch comes from the follower,
// update its corresponding log end offset
if(Request.isValidBrokerId(replicaId))
updateFollowerLogReadResults(replicaId, logReadResults)
Follower更新
Follower从Leader拉取消息的处理逻辑(ReplicaFetcherThread线程processPartitionData)如下:
- 写入消息到本地磁盘。
- 更新LEO值。
- 更新高水位值。
i. 获取Leader发送的高水位值:currentHW。
ii. 获取步骤2中更新过的LEO值:currentLEO。
iii. 更新高水位为min(currentHW, currentLEO)。
//获取本地副本
val replica = replicaMgr.getReplica(topicPartition).get
//获取新拉取的数据
val records = partitionData.toRecords
//写入消息到本地磁盘并更新leo
replica.log.get.append(records, assignOffsets = false, replica.log.get.config.followerAppendCacheEnable)
//更新 hw = min(currentHW, currentLEO)
val followerHighWatermark = replica.logEndOffset.messageOffset.min(partitionData.highWatermark)
replica.highWatermark = new LogOffsetMetadata(followerHighWatermark)
同步过程中,Follower有两种可能会发生截断:
- Follower副本 fetch数据时发现LEO > Leader的startOffset(Unclean leader election)
- Follower副本 fetch数据时发现LEO < Leader LSO,落后太多了
//1. LEO > Leader LEO(Unclean leader election)
if (leaderEndOffset < replica.logEndOffset.messageOffset) {
replicaMgr.logManager.truncateTo(Map(topicPartition -> leaderEndOffset))
}else{
// 2.LEO < Leader LSO,落后太多了
if (leaderStartOffset > replica.logEndOffset.messageOffset)
replicaMgr.logManager.truncateFullyAndStartAt(topicPartition, leaderStartOffset)
}
过一下流程
选自 《极客时间-关于高水位和Leader Epoch的讨论》
搞清楚了这些值的更新机制之后,我来举一个实际的例子,说明一下Kafka副本同步的全流程。该例子使用一个单分区且有两个副本的主题。
当生产者发送一条消息时,Leader和Follower副本对应的高水位是怎么被更新的呢?我给出了一些图片,我们一一来看。
首先是初始状态。下面这张图中的remote LEO就是刚才的远程副本的LEO值。在初始状态时,所有值都是0。

当生产者给主题分区发送一条消息后,状态变更为:
此时,Leader副本成功将消息写入了本地磁盘,故LEO值被更新为1。
Follower再次尝试从Leader拉取消息。和之前不同的是,这次有消息可以拉取了,因此状态进一步变更为:
这时,Follower副本也成功地更新LEO为1。此时,Leader和Follower副本的LEO都是1,但各自的高水位依然是0,还没有被更新。它们需要在下一轮的拉取中被更新,如下图所示:
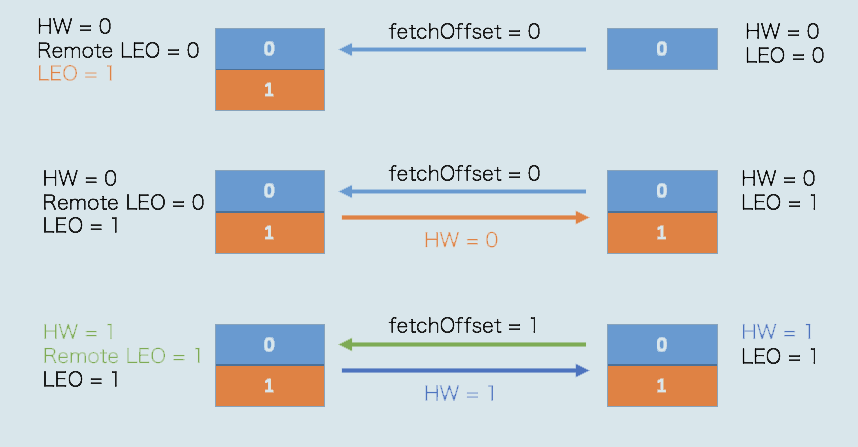
在新一轮的拉取请求中,由于位移值是0的消息已经拉取成功,因此Follower副本这次请求拉取的是位移值=1的消息。Leader副本接收到此请求后,更新远程副本LEO为1,然后更新Leader高水位为1。做完这些之后,它会将当前已更新过的高水位值1发送给Follower副本。Follower副本接收到以后,也将自己的高水位值更新成1。至此,一次完整的消息同步周期就结束了。事实上,Kafka就是利用这样的机制,实现了Leader和Follower副本之间的同步。
Follower副本的高水位更新需要一轮额外的拉取请求才能实现。如果把上面那个例子扩展到多个Follower副本,情况可能更糟,也许需要多轮拉取请求。也就是说,Leader副本高水位更新和Follower副本高水位更新在时间上是存在错配的。这种错配是很多“数据丢失”或“数据不一致”问题的根源。
Leader选举时hw变更
LeaderAndIsrRequest请求的处理逻辑:
- 校验Controller Epoch(和Leader Epoch)是否过期
- 将分区分类成两个集合,一个是把该Broker当成Leader的所有分区;一个是把该Broker当成Follower的所有分区
- 调用makeLeaders和makeFollowers方法,正式让Leader和Follower角色生效
- 如果是第一次接受LeaderAndIsrRequest请求(即broker新启动),启动highwatermark-checkpoint定时任务不断将hw写入本地进行持久化,待后续创建本地Replica时读取
/*-----------------------------------------------------------------------------
* ReplicaManager#becomeLeaderOrFollower
* 根据LeaderAndIsrRequest.partitionStates判断本broker的各分区是leader还是follower
*/
// 确定Broker上副本是哪些分区的Leader副本
val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>
stateInfo.leader == localBrokerId
}
// 确定Broker上副本是哪些分区的Follower副本
val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keys
// 调用makeLeaders方法为partitionsToBeLeader所有分区执行"成为Leader副本"的逻辑
val partitionsBecomeLeader =
if (partitionsTobeLeader.nonEmpty)
makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)
else
Set.empty[Partition]
// we initialize highwatermark thread after the first leaderisrrequest. This ensures that all the partitions
// have been completely populated before starting the checkpointing there by avoiding weird race conditions
if (!hwThreadInitialized) {
// 启动定时任务持久化hw
startHighWaterMarksCheckPointThread()
hwThreadInitialized = true
}
replicaFetcherManager.shutdownIdleFetcherThreads()
Leader
Make the current broker to become leader for a given set of partitions by:
- Stop fetchers for these partitions
- Update the partition metadata in cache:
- 更新controller epoch
- 设置LeaderAndIsrRequest返回的所有副本
- 设置LeaderAndIsrRequest返回的Isr副本
- 由follower变为leader时,读取本地log持久化保存的HW, 设为自身(即leaderReplica)的HW.
- Add these partitions to the leader partitions set
/*-----------------------------------------------------------------------------
* Partition#makeLeader
* 使本地partition副本成为Leader副本
*/
//1.更新controller epoch
controllerEpoch = partitionStateInfo.controllerEpoch
//2.设置:LeaderAndIsrRequest返回的所有有效副本
val allReplicas = partitionStateInfo.replicas.asScala.map(_.toInt)
allReplicas.foreach(replica => getOrCreateReplica(replica))
//3. 设置:LeaderAndIsrRequest返回的Isr副本
val newInSyncReplicas = partitionStateInfo.isr.asScala.map(r => getOrCreateReplica(r)).toSet
// remove assigned replicas that have been removed by the controller
(assignedReplicas.map(_.brokerId) -- allReplicas).foreach(removeReplica)
inSyncReplicas = newInSyncReplicas
if (isNewLeader) {
// 4. construct the high watermark metadata for the new leader replica
leaderReplica.convertHWToLocalOffsetMetadata()
// reset log end offset for remote replicas
assignedReplicas.filter(_.brokerId != localBrokerId).foreach(_.updateLogReadResult(LogReadResult.UnknownLogReadResult))
}
(maybeIncrementLeaderHW(leaderReplica), isNewLeader)
**Follower **
- 更新_controller Epoch_
- 保存副本列表(Assigned Replicas,AR)并且清空ISR
- 移除现有Fetcher线程 replicaFetcherManager
- 将分区日志截断到hw
// 使本地partition副本成为Follower副本
partitionState.foreach{ case (partition, partitionStateInfo) =>
if (partition.makeFollower(controllerId, partitionStateInfo, correlationId))
partitionsToMakeFollower += partition
}
// 移除现有Fetcher线程
replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))
//日志截断到hw
logManager.truncateTo(partitionsToMakeFollower.map {
partition =>(partition.topicPartition,
partition.getOrCreateReplica().highWatermark.messageOffset)
}.toMap)
/*-----------------------------------------------------------------------------
* Partition#makeFollower
* 使本地partition副本成为Follower副本
*/
controllerEpoch = partitionStateInfo.controllerEpoch
val newLeaderBrokerId: Int = partitionStateInfo.leader
//保存副本列表(Assigned Replicas,AR)并且清空ISR
val allReplicas = partitionStateInfo.replicas.asScala.map(_.toInt)
allReplicas.foreach(r => getOrCreateReplica(r))
inSyncReplicas = Set.empty[Replica]
问题与改进
下面内容选自KIP101。
问题
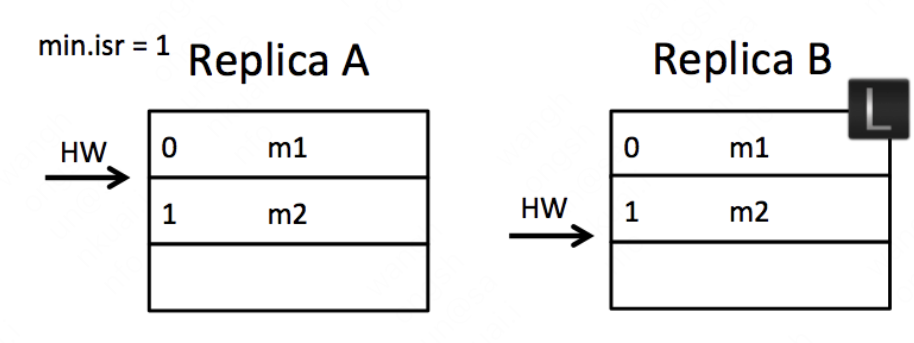
在副本同步一节中,我们可以看到整个过程中Leader副本和Follower副本之间的HW同步又一个间隙,需要再额外一轮的FetchRequest/FetchResponse。在这个间隙中发生异常,有可能会产生数据不一致或者数据丢失。接下来分析一下:
case 1 数据丢失
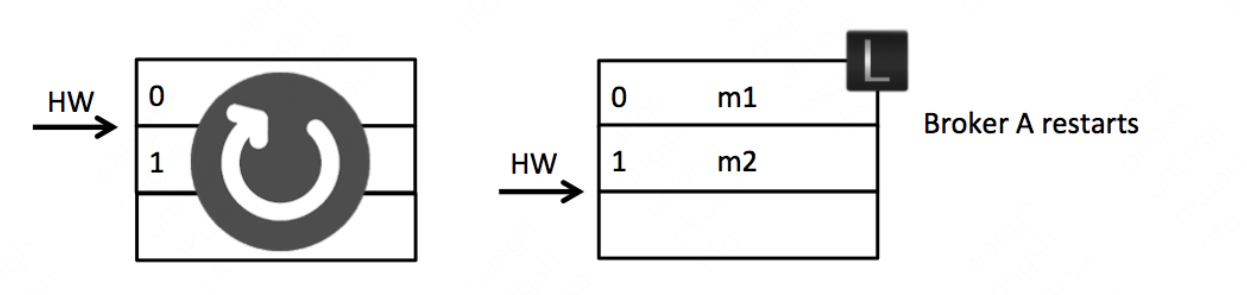
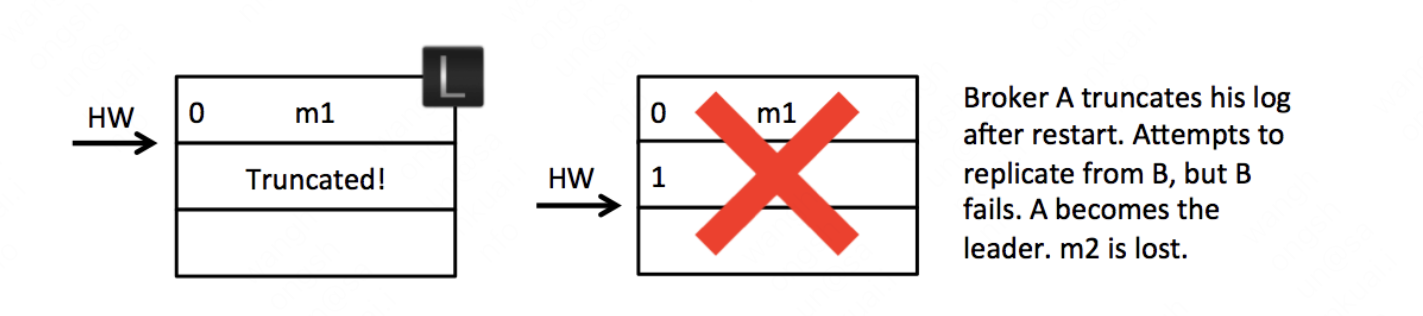
如果在上图初始状态时,A宕机了,那么在A重启之后会根据之前HW位置(这个值会存入本地的复制点文件replication-offset-checkpoint)进行日志阶段,这样便会将M2这条消息删除,此时A只剩下m1这一条消息,之后A再向B发生FetchRequest请求拉取消息。
此时,若B再宕机,那么A就会被选举为新的leader, B恢复之后会成为follower, 由于follower副本HW不能比leader副班的hw高,所以还会做一次日志接单,因此将HW调整为1,那么m2这条消息就丢失了。
case2 数据不一致
这种情况应该出现在允许unclean选举时。假设B挂掉,然后A挂掉,两者的数据和hw不同步:
然后B第一个恢复过来并成为leader,并写入消息m3: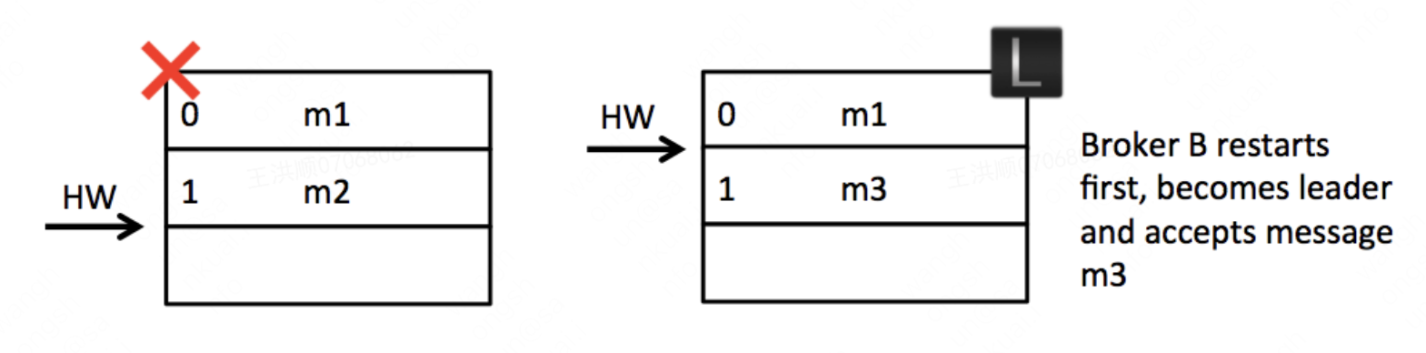
之后A恢复过来,发现hw=2,无需截断,就发生了数据不一致: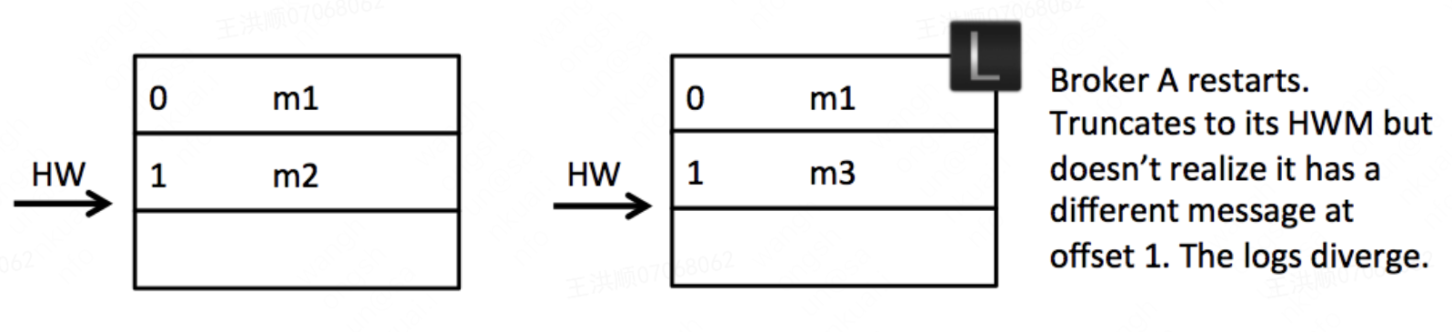
leader epoch
为了解决上述两种问题,Kafka从0.11.0.0开始引入来leader epoch的概念,在需要截断数据的时候使用leader epoch的概念,在需要截断数据的时候使用leader epoch作为参考依据而不是原本的HW。leader epoch代表leader的纪元信息(epoch),初始值为0。每当leader变更一次, leader epoch的值就会加1,相当于为leader增设来一个版本号。于此同时,每个副本还会增设一个矢量**<LeaderEpoch => StartOffset>**, 其中StartOffset表示当前LeaderEpoch写入的第一条消息的偏移量。每个Log下都有一个leader-epoch-checkpoint文件,在发生leader epoch变更时,会将对应的矢量对追加到这个文件中。
以数据丢失为例子,看一下leader epoch的流程:
首先可以看到分区比之前多了LeaderEpoch: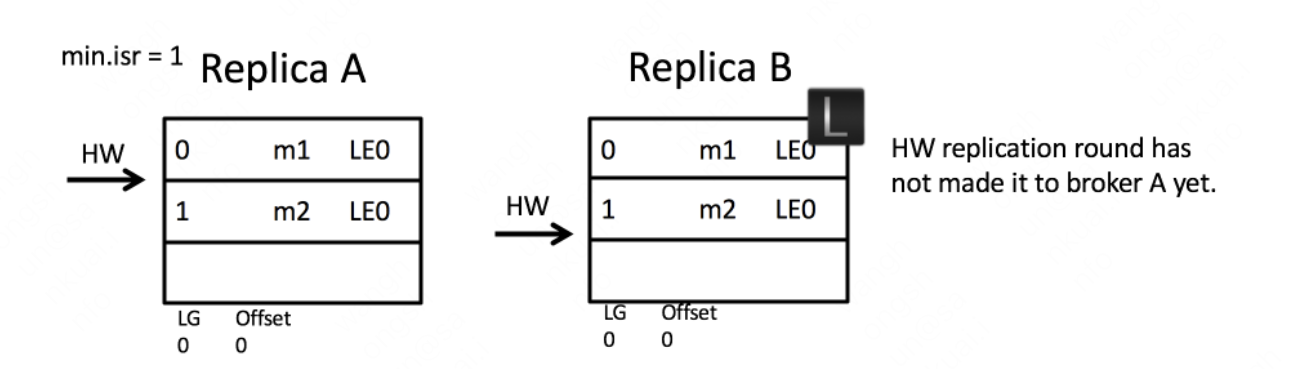
然后,同样A发生重启,之后A不是先忙着截断日志而是先发送OffsetForLeaderEpochRequest请求(包含A当前的LeaderEpoch)给B。
如果A中的LeaderEpoch(假设为LE_A)和B中不同,那么B此时会查找LeaderEpoch为LE_A + 1对应的StartOffset并返回给A,也就是LE_A版本对应的LEO, 所以我们可以将OffsetsForLeaderEpochRequest的请求看作用来查找follower副本当前LeaderEpoch的LEO。

A收到2之后发现和目前的LEO相同,就不需要截断日志来。否则需要截断到返回到的LE_A版本对应的LEO(如case2会发现返回到LEO值更小,发生截断)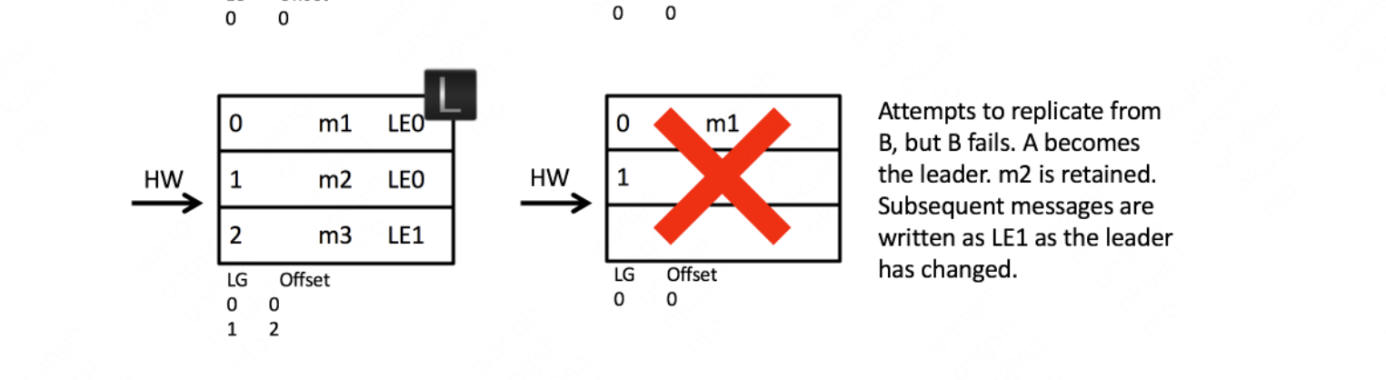
不仅解决了上面两种问题,而且减少了不必要的日志截断( 空间换性能)
参考
极客时间-Kafka核心技术与实战
极客时间-Kafka核心源码解读
KIP101
《深入理解Kafka核心设计与实践原理》