Kafka数据同步1:Flink容错机制
Kafka数据同步1:Flink容错机制
由于Flink中的两阶段实现协议的一些主体部分,如beginTransaction、commit、preCommit、abort的逻辑都是由用户自己实现的。借助这篇博客学习两阶段提交协议(two-phase commit)。
1. 两阶段提交two-phase commit
以下内容Copy from:DDIA
1.1 简介
两阶段提交(two-phase commit) 是一种用于实现跨多个节点的原子事务提交的算法,即确保所有节点提交或所有节点中止。 它是分布式数据库中的经典算法。2PC中的提交/中止过程分为两个阶段(因此而得名),而不是单节点事务中的单个提交请求。

2PC使用一个通常不会出现在单节点事务中的新组件:协调者(coordinator)(也称为事务管理器(transaction manager))。协调者通常在请求事务的相同应用进程中以库的形式实现(例如,嵌入在Java EE容器中),但也可以是单独的进程或服务。这种协调者的例子包括Narayana,JOTM,BTM或MSDTC。
正常情况下,2PC事务以应用在多个数据库节点上读写数据开始。我们称这些数据库节点为参与者(participants)。当应用准备提交时,协调者开始阶段 1 :它发送一个准备(prepare)请求到每个节点,询问它们是否能够提交。然后协调者会跟踪参与者的响应:
- 如果所有参与者都回答“是”,表示它们已经准备好提交,那么协调者在阶段 2 发出提交(commit)请求,然后提交真正发生。
- 如果任意一个参与者回复了“否”,则协调者在阶段2 中向所有节点发送中止(abort)请求。
1.2 系统承诺
这个简短的描述可能并没有说清楚为什么两阶段提交保证了原子性,而跨多个节点的一阶段提交却没有。在两阶段提交的情况下,准备请求和提交请求当然也可以轻易丢失。 2PC又有什么不同呢?
为了理解它的工作原理,我们必须更详细地分解这个过程:
- 当应用想要启动一个分布式事务时,它向协调者请求一个事务ID。此事务ID是全局唯一的。
- 应用在每个参与者上启动单节点事务,并在单节点事务上捎带上这个全局事务ID。所有的读写都是在这些单节点事务中各自完成的。如果在这个阶段出现任何问题(例如,节点崩溃或请求超时),则协调者或任何参与者都可以中止。
- 当应用准备提交时,协调者向所有参与者发送一个准备请求,并打上全局事务ID的标记。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务ID的中止请求。
- 参与者收到准备请求时,需要确保在任意情况下都的确可以提交事务。这包括将所有事务数据写入磁盘(出现故障,电源故障,或硬盘空间不足都不能是稍后拒绝提交的理由)以及检查是否存在任何冲突或违反约束。通过向协调者回答“是”,节点承诺,只要请求,这个事务一定可以不出差错地提交。 换句话说,参与者放弃了中止事务的权利,但没有实际提交。
- 当协调者收到所有准备请求的答复时,会就提交或中止事务作出明确的决定(只有在所有参与者投赞成票的情况下才会提交)。协调者必须把这个决定写到磁盘上的事务日志中,如果它随后就崩溃,恢复后也能知道自己所做的决定。这被称为提交点(commit point)。
- 一旦协调者的决定落盘,提交或放弃请求会发送给所有参与者。如果这个请求失败或超时,协调者必须永远保持重试,直到成功为止。没有回头路:如果已经做出决定,不管需要多少次重试它都必须被执行。 如果参与者在此期间崩溃,事务将在其恢复后提交——由于参与者投了赞成,因此恢复后它不能拒绝提交。
因此,该协议包含两个关键的“不归路”点:当参与者投票“是”时,它承诺它稍后肯定能够提交(尽管协调者可能仍然选择放弃)。一旦协调者做出决定,这一决定是不可撤销的。这些承诺保证了2PC的原子性。 (单节点原子提交将这两个事件混为一谈:将提交记录写入事务日志。)
1.3 协调者失效
我们已经讨论了在2PC期间,如果参与者之一或网络发生故障时会发生什么情况:如果任何一个准备请求失败或者超时,协调者就会中止事务。如果任何提交或中止请求失败,协调者将无条件重试。但是如果协调者崩溃,会发生什么情况就不太清楚了。
如果协调者在发送准备请求之前失败,参与者可以安全地中止事务。但是,一旦参与者收到了准备请求并投了“是”,就不能再单方面放弃 —— 必须等待协调者回答事务是否已经提交或中止。如果此时协调者崩溃或网络出现故障,参与者什么也做不了只能等待。 参与者的这种事务状态称为 存疑(in doubt) 的或 不确定(uncertain) 的。
如下图 所示。在这个特定的例子中,协调者实际上决定提交,数据库2 收到提交请求。但是,协调者在将提交请求发送到数据库1 之前发生崩溃,因此数据库1 不知道是否提交或中止。即使超时在这里也没有帮助:如果数据库1 在超时后单方面中止,它将最终与执行提交的数据库2 不一致。同样,单方面提交也是不安全的,因为另一个参与者可能已经中止了。

没有协调者的消息,参与者无法知道是提交还是放弃。原则上参与者可以相互沟通,找出每个参与者是如何投票的,并达成一致,但这不是2PC协议的一部分。
可以完成2PC的唯一方法是等待协调者恢复。这就是为什么协调者必须在向参与者发送提交或中止请求之前,将其提交或中止决定写入磁盘上的事务日志:协调者恢复后,通过读取其事务日志来确定所有存疑事务的状态。任何在协调者日志中没有提交记录的事务都会中止。因此,2PC的提交点归结为协调者上的常规单节点原子提交。
2. Flink 容错机制
2.1 核心思想
首先看整体看一下,Flink容错机制的核心思想:
The central part of Flink’s fault tolerance mechanism is drawing consistent snapshots of the distributed data stream and operator state. These snapshots act as consistent checkpoints to which the system can fall back in case of a failure.
Flink implements fault tolerance using a combination of stream replay and checkpointing. A checkpoint marks a specific point in each of the input streams along with the corresponding state for each of the operators. A streaming dataflow can be resumed from a checkpoint while maintaining consistency (exactly-once processing semantics) by restoring the state of the operators and replaying the records from the point of the checkpoint.
-
容错机制通过持续创建分布式数据流和算子状态的快照来实现。这需要存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)
-
在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operator ,重置其到最近成功的 checkpoint,在根据checkpoint找到对应的快照来恢复state。
-
根据state中保存的信息,进行stream replay。
- 为了成功replay,需要有能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)
- 重放时要保证每条数据都只执行exactly-once或者at-least-once。如果强要求exactly-once , 需要消除介于[上一次checkoint,故障点]之间的操作的影响,比如rollback操作、幂等性操作。
然后再具体看每个细节:
-
快照保存什么信息?
-
何时保存快照,以及如何恢复到最近的快照? checkpointing机制。
-
快照保存在哪里?state backends。
-
进行stream replay如何保证exactly-once。
2.2 checkpointing
A checkpoint in Flink is a consistent snapshot of:
- The current state of an application
- The position in an input stream
Flink 容错机制的核心部分是通过持续创建分布式数据流和算子状态的快照。这些快照充当一致的检查点(snapshots),系统可以在发生故障时回退到这些检查点(checkpoints)。
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。

Checkpoint n 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件 后而生成的状态。
当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。 拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。

Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。
2.3 state backend

由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
Flink 管理的状态存储在 state backend 中。Flink 有两种 state backend 的实现 :
- 一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上的,
- 另一种基于堆的 state backend,将其工作状态保存在 Java 的堆内存中。这种基于堆的 state backend 有两种类:
- FsStateBackend,将其状态快照持久化到分布式文件系统;
- MemoryStateBackend,它使用 JobManager 的堆保存状态快照。
所有这些 state backends 都能够异步执行快照,这意味着它们可以在不妨碍正在进行的流处理的情况下执行快照。
2.4 算子生命周期
// 初始化阶段
OPERATOR::setup
UDF::setRuntimeContext
OPERATOR::initializeState
OPERATOR::open
UDF::open
// 处理阶段(对每个 element 或 watermark 调用)
OPERATOR::processElement
UDF::run
OPERATOR::processWatermark
// checkpointing 阶段(对每个 checkpoint 异步调用)
OPERATOR::snapshotState
// 通知 operator 处理记录的过程结束
OPERATOR::finish
// 结束阶段
OPERATOR::close
UDF::close
算子通过 initializeState() 恢复状态。
checkpoint barriers 会调用(异步)snapshotState() 方法触发 checkpoint。
2.5 exactly-once
When we say “exactly-once semantics”, what we mean is that each incoming event affects the final results exactly once. Even in case of a machine or software failure, there’s no duplicate data and no data that goes unprocessed.
Flink对内部的状态通过checkpionting机制来保证 exactly-once:如果机器或软件发生故障并在重新启动时,Flink 应用程序会从最近成功完成的checkpoint恢复处理;Flink 恢复应用程序state并从ckeckpoint回滚到输入流中的相应开始位置,然后再次开始处理,而在此checkpoint之后事件生成的state不可见。这意味着 Flink 计算结果时就好像失败从未发生过一样。
但是 Flink 应用程序与各种data sinks一起运行,为了提供端到端的Exactly-once语义,仅仅保证Flink应用程序的状态符合Exactly-once语义是不够的,这些语义也适用于Flink写入的外部系统。这些外部系统必须提供一种提交或回滚写入的方法与 Flink 的检查点相协调。
在分布式系统中协调提交和回滚的一种常见方法是两阶段提交协议。Flink 通过 TwoPhaseCommitSinkFunction 利用两阶段提交协议来提供端到端的精确一次语义。
3. End-to-End Exactly-Once Processing in Apache Flink
Copy From : Apache Flink官方文档之An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
以Kafka为例,讨论一下Flink 如何通过 TwoPhaseCommitSinkFunction 利用两阶段提交协议来提供端到端的精确一次语义。
3.1 设计思想

在我们今天将讨论的示例 Flink 应用程序中,我们有:
- 从 Kafka 读取的数据源(在 Flink 中,一个 KafkaConsumer)
- 窗口聚合
- 将数据写回 Kafka 的数据接收器(在 Flink 中,一个 KafkaProducer)
两阶段提交协议的“预提交”(pre-commit)阶段从检查点开始。当一个检查点开始时,Flink JobManager 会向数据流中注入一个检查点屏障checkpoint barrier (它将数据流中的记录分为进入当前检查点的集合与进入下一个检查点的集合)。
checkpoint barrier 在算子直接传递。对每个算子,它会触发算子的state backend以获取其状态的快照。

Datasource存储其 Kafka 偏移量,并在完成此操作后,将checkpoint barrier 传递给下一个算子。
如果运算符仅具有内部状态(Internal State),则此方法有效。内部状态是由 Flink 的状态后端存储和管理的所有内容 。例如,第二个运算符中的窗口和。当一次处理只有内部状态时,除了在检查点之前更新状态后端中的数据之外,在预提交期间不需要执行任何其他操作。Flink 负责在检查点成功的情况下正确提交这些写入,或者在失败的情况下中止它们。
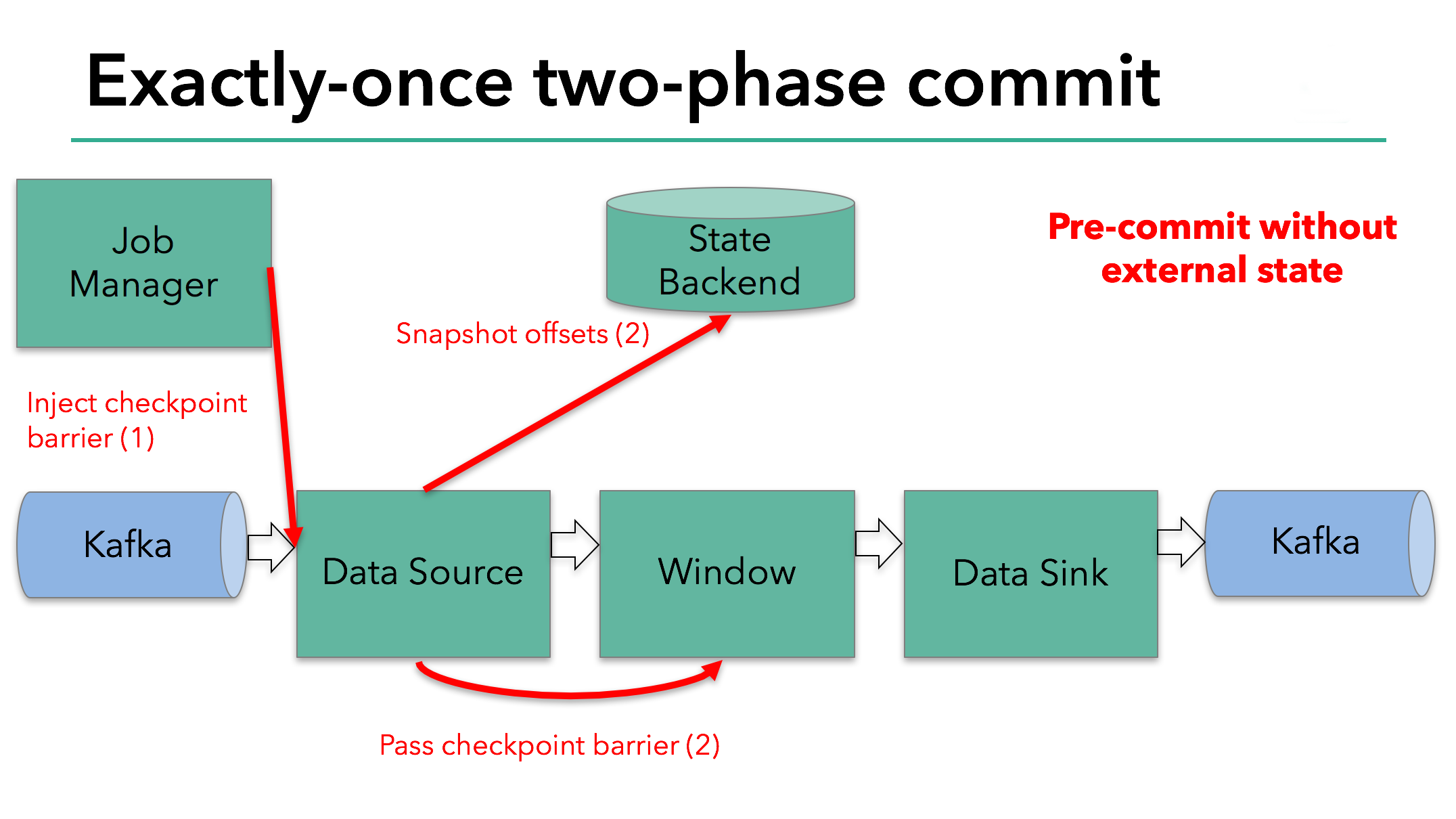
但是,当进程具有外部状态(external state)时,该状态的处理方式必须稍有不同。外部状态通常以写入外部系统(如 Kafka)的形式出现。在这种情况下,为了提供 exactly-once 的保证,外部系统必须为与两阶段提交协议集成的事务提供支持。
我们知道我们示例中的data sink具有这样的external state,因为它正在将数据写入 Kafka。在这种情况下,在预提交pre-commit阶段,data sink除了将其状态写入state backend 外,还必须预先提交其外部事务。

当check point通过所有算子并且触发的快照回调(snapshot callbacks)完成时,预提交pre-commit阶段结束。此时检查点成功完成并包含整个应用程序的状态,包括预先提交的外部状态。如果发生故障,我们将从该检查点重新初始化应用程序。
下一步是通知所有operator检查点已成功。这是两阶段提交协议的提交阶段,JobManager 为应用程序中的每个operator发出检查点完成的回调。
data source和window operator没有外部状态,因此在提交阶段,这些算子不必采取任何行动。但是,数据接收器确实具有外部状态,并使用外部写入提交事务。

我们来总结一下:
-
一旦所有operator完成他们的pre-commit,他们就会发出一个commit。
-
如果至少一个pre-commit失败,所有其他的都将被中止,我们回滚(rollback)到上一个成功完成的checkpoint。
-
成功预提交后,必须保证提交最终成功。我们的operator和我们的外部系统都需要做出这种保证。如果一次提交失败(例如由于间歇性网络问题),整个 Flink 应用程序失败,根据用户的重启策略重新启动,要有另一次提交尝试。这个过程很关键,因为如果提交最终没有成功,就会发生数据丢失。
因此,我们可以确定所有operator都同意检查点的最终结果:所有operator都同意数据要么被提交,要么提交被中止并回滚。
3.2 参考实现
让我们在一个简单的示例中讨论如何扩展 TwoPhaseCommitSinkFunction。我们只需要实现四个方法,实现一个exactly-once file sink:
-
beginTransaction:为了开始事务,我们在目标文件系统的临时目录中创建一个临时文件。随后,我们可以在处理该文件时将数据写入该文件。
-
preCommit:在预提交时,我们flush文件,并且关闭不再写入它。我们还将为属于下一个检查点的任何后续写入启动一个新事务。
-
commit:在提交时,我们以原子方式将预先提交的文件移动到实际的目标目录。请注意,这会增加output data 可见性的延迟。
-
abort: 在中止时,我们删除临时文件。
3.3 设计时需要考虑的问题
-
Q1 Pre-commit阶段:如果在pre-commit阶段发生故障,任务重启后,我们将从最近的检查点重新初始化应用程序,Flink state会恢复自动到上一次检查点时的状态。但是如何rollback外部数据库的pre-commit事务, 并且何时rollback?
-
Q2 commit阶段:如果在pre-commit和commit之间发生故障,任务重启后如何保证最终提交成功?
-
Q3 Coordinator故障:如果整个Flink集群挂掉或者Coordinator(Job Manager)故障,在新的集群中重启Job,state丢失,无法使用checkpoint来恢复,这时候如何进行恢复?
4. 异步设计时如何保证至少At-Least
为了提高写数据的速度,常见的经典设计是 数据池 + Sender线程, 即:
