Kafka数据同步2: FlinkKafkaConsumerBase
Kafka数据同步2: FlinkKafkaConsumerBase
前言
正如我们在上一篇《Kafka数据同步1: Flink容错机制》所说:
Flink 容错机制通过持续创建分布式数据流和算子状态的快照来实现。在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operatr ,重置其到最近成功的 checkpoint。再根据checkpoint找到对应的快照来恢复state,进行stream replay。
Stream Replay需要满足俩个条件:
- 为了成功replay,需要有能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)
- 重放时要保证每条数据都只执行exactly-once或者at-least-once。如果强要求exactly-once , 需要消除介于[上一次checkoint,故障点]之间的操作的影响,比如rollback操作、幂等性操作。
本篇从数据源的角度出发,以Flink官方提供的FlinkKafkaConsumerBase为例, 看一下如何实现一个可重放的Data Source。所有Kafka同步工具,其数据同步都是从FlinkKafkaConsumerBase开始的。
1. SourceFunction原理
Copy From 《Flink SourceFunction 初了解》
1.1 SourceFunction
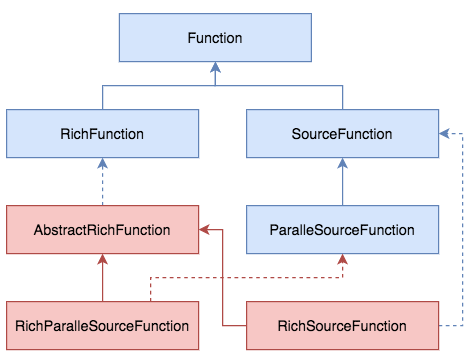
SourceFunction 是 Flink 中所有流数据 Source 的基本接口。SourceFunction 接口继承了 Function 接口,并在内部定义了:
- run() 方法: 数据读取使用
- cancel() 方法: 取消运行
- SourceContext 内部接口: 输出元素
public interface SourceFunction<T> extends Function, Serializable {
void run(SourceContext<T> ctx) throws Exception;
void cancel();
interface SourceContext<T> {
void collect(T element);
void collectWithTimestamp(T element, long timestamp);
void emitWatermark(Watermark mark);
void markAsTemporarilyIdle();
Object getCheckpointLock();
void close();
}
}
当 Source 输出元素时,可以 在 run 方法中调用 SourceContext 接口的 collect 或者 collectWithTimestamp 方法输出元素。 run 方法需要尽可能的一直运行,因此大多数 Source 在 run 方法中都有一个 while 循环。Source 也必须具有响应 cancel 方法调用中断 while 循环的能力。比较通用的模式是添加 volatile 布尔类型变量 isRunning 来表示是否在运行中。在 cancel 方法中设置为 false,并在循环条件中检查该变量是否为 true:
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<T> ctx) throws Exception {
while (isRunning && otherCondition == true) {
ctx.collect(xxx);
}
}
@Override
public void cancel() {
isRunning = false;
}
在默认情况下,SourceFunction 不支持并行读取数据,因此 SourceFunction 被 ParallelSourceFunction 接口继承,以支持对外部数据源中数据的并行读取操作:
public interface ParallelSourceFunction<OUT> extends SourceFunction<OUT> {
}
RichParallelSourceFunction 是用于实现并行 Source 的基类。 Runtime 会执行与 Source 配置的并行度一样多的此函数的并行实例。Source 还可以通过 AbstractRichFunction.getRuntimeContext() 访问上下文信息,例如通过 getRuntimeContext().getNumberOfParallelSubtasks() 获取并行实例的数量,通过getRuntimeContext().getIndexOfThisSubtask() 获取当前实例是哪个并行实例。
1.2 SourceContext
Flink 将 Source 的运行机制跟发送元素进行了分离。具体如何发送元素,取决于独立内部接口 SourceContext。SourceFunction 以内部接口的方式定义了该上下文接口对象:
public interface SourceFunction<T> extends Function, Serializable {
...
interface SourceContext<T> {
void collect(T element);
void collectWithTimestamp(T element, long timestamp);
void emitWatermark(Watermark mark);
void markAsTemporarilyIdle();
Object getCheckpointLock();
void close();
}
}
SourceContext 定义了数据接入过程用到的上下文信息,包含如下方法:
- collect():用于收集从外部数据源读取的数据并下发到下游算子中。
- collectWithTimestamp():用于支持收集数据元素以及 EventTime 时间戳。
- emitWatermark():用于在 SourceFunction 中生成 Watermark 并发送到下游算子进行处理。
- getCheckpointLock():用于获取检查点锁(Checkpoint Lock),例如使用 KafkaConsumer 读取数据时,可以使用检查点锁,确保记录发出的原子性和偏移状态更新。
2. 继承关系
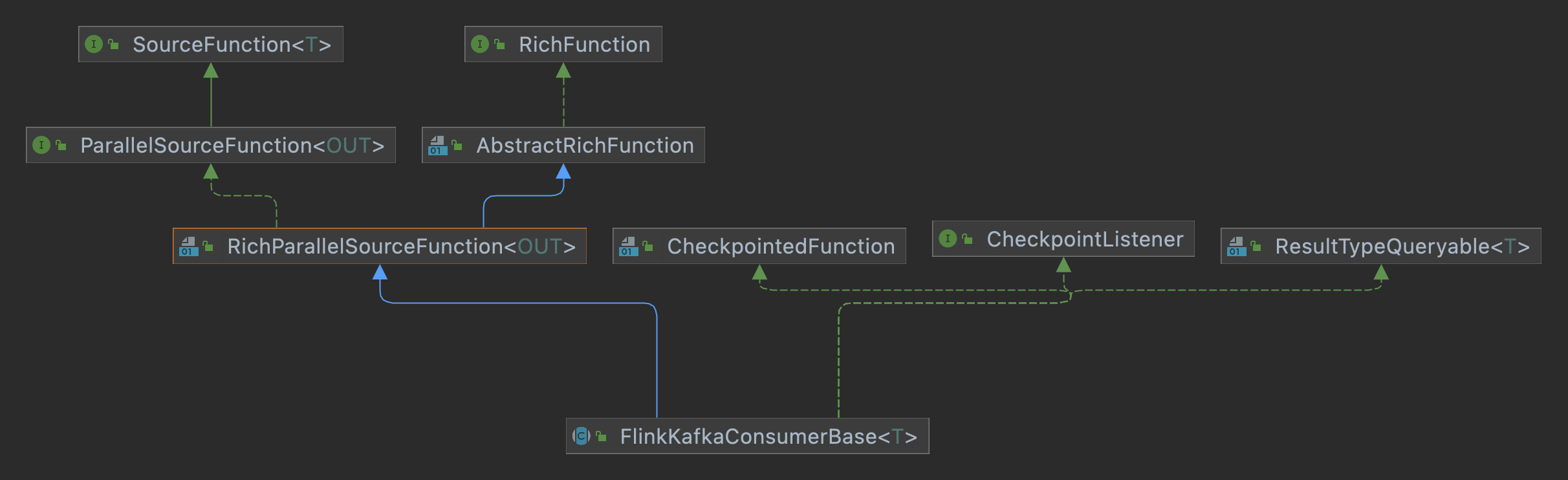
首先看一下KafkaConsumer的继承关系,可以有大致的推测:
- extends RichParallelSourceFunction: 支持并行读。
- implements CheckpointedFunction: 支持checkpoint机制,对state进行快照备份,用来提供容错机制。
- implements CheckpointListener:支持2-pc功能。
3 数据读取

3.1 run
首先从KafkaConsumer的run方法,可以看看数据读取的大致逻辑:通过Fetcher源源不断地读取数据,然后通过SourceContext.collect方法输出:
//org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase#run
@Override
public void run(SourceContext<T> sourceContext) throws Exception {
...
this.kafkaFetcher = createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
periodicWatermarkAssigner,
punctuatedWatermarkAssigner,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
if (!running) {
return;
}
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
}
3.2 AbstractFetcher
Fetcher源源不断地读取数据,然后通过SourceContext.collect方法输出。
//org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher
@Override
public void runFetchLoop() throws Exception {
try {
final Handover handover = this.handover;
// kick off the actual Kafka consumer
consumerThread.start();
while (running) {
// this blocks until we get the next records
// it automatically re-throws exceptions encountered in the consumer thread
final ConsumerRecords<byte[], byte[]> records = handover.pollNext();
// get the records for each topic partition
for (KafkaTopicPartitionState<TopicPartition> partition : subscribedPartitionStates()) {
List<ConsumerRecord<byte[], byte[]>> partitionRecords =
records.records(partition.getKafkaPartitionHandle());
for (ConsumerRecord<byte[], byte[]> record : partitionRecords) {
final T value = deserializer.deserialize(record);
if (deserializer.isEndOfStream(value)) {
// end of stream signaled
running = false;
break;
}
// emit the actual record. this also updates offset state atomically
// and deals with timestamps and watermark generation
emitRecord(value, partition, record.offset(), record);
}
}
}
}
finally {
// this signals the consumer thread that no more work is to be done
consumerThread.shutdown();
}
3.3 Handover
Handover是KafkaConsumerThread 和 Fetcher 通信的信息载体(共享变量),包含error和一批record。
public final class Handover implements Closeable {
// 消息体
private ConsumerRecords<byte[], byte[]> next;
//error信息
private Throwable error;
private boolean wakeupProducer;
}
Handover的读写可以看着一个容量为1的阻塞队列,从而保证 KafkaConsumerThread生产消息 -> Fetcher消费消息->KafkaConsumerThread生产消息 -> Fetcher消费消息.... 的先后顺序。从而保证只要一批消息被算子拉取之后,才拉取下一批数据。(kafkaConsumerThread会解释为何如此设计)
/**
* Polls the next element from the Handover, possibly blocking until the next element is
* available. This method behaves similar to polling from a blocking queue.
*/
@Nonnull
public ConsumerRecords<byte[], byte[]> pollNext() throws Exception {
synchronized (lock) {
while (next == null && error == null) {
lock.wait();
}
ConsumerRecords<byte[], byte[]> n = next;
if (n != null) {
next = null;
lock.notifyAll();
return n;
}
else {
ExceptionUtils.rethrowException(error, error.getMessage());
// this statement cannot be reached since the above method always throws an exception
// this is only here to silence the compiler and any warnings
return ConsumerRecords.empty();
}
}
}
/**
* Hands over an element from the producer. If the Handover already has an element that was not yet picked up by the consumer thread, this call blocks until the consumer picks up that previous element.
* This behavior is similar to a "size one" blocking queue.
*/
public void produce(final ConsumerRecords<byte[], byte[]> element)
throws InterruptedException, WakeupException, ClosedException {
checkNotNull(element);
synchronized (lock) {
//只有为空时才能写入
while (next != null && !wakeupProducer) {
lock.wait();
}
wakeupProducer = false;
// if there is still an element, we must have been woken up
if (next != null) {
throw new WakeupException();
}
// if there is no error, then this is open and can accept this element
else if (error == null) {
next = element;
lock.notifyAll();
}
// an error marks this as closed for the producer
else {
throw new ClosedException();
}
}
}
3.4 KafkaConsumerThread
KafkaConsumerThread定期 拉取数据 和 提交位移commit。通过Handover的存取机制保证每一次迭代开始前,上一批拉取的数据已经被消费。然后本轮迭代先提交offset commit, 再拉取下一批数据。
由此可见,KafkaConsumerThread消费速度取决于三个因素:
- Kafka提供消息的速度。
- Flink消费的速度。
- rateLimiter限流的速度
//org.apache.flink.streaming.connectors.kafka.internals.KafkaConsumerThread#run
@Override
public void run() {
// this is the means to talk to FlinkKafkaConsumer's main thread
final Handover handover = this.handover;
this.consumer = getConsumer(kafkaProperties);
...
// main fetch loop
while (running) {
// 1.提交offset
// get and reset the work-to-be committed, so we don't repeatedly commit the same
final Tuple2<Map<TopicPartition, OffsetAndMetadata>, KafkaCommitCallback> commitOffsetsAndCallback =
nextOffsetsToCommit.getAndSet(null);
if (commitOffsetsAndCallback != null) {
log.debug("Sending async offset commit request to Kafka broker");
// also record that a commit is already in progress
// the order here matters! first set the flag, then send the commit command.
commitInProgress = true;
consumer.commitAsync(commitOffsetsAndCallback.f0, new CommitCallback(commitOffsetsAndCallback.f1));
}
}
...
// 2. 拉取数据
if (records == null) {
records = getRecordsFromKafka();
}
// 3. 写入到handover
handover.produce(records);
...
}
4. checkpoint机制容错
按照前面的问题看似已经完美无缺,无需额外保障:通过Handover的存取机制保证每一次迭代开始前,上一批拉取的数据已经被消费。然后本轮迭代先提交offset commit, 再拉取下一批数据。即使系统宕机,重启也应该从没有消费的消息开始。
但是!上面只能保证上一批数据被Data Souce消费,并不能保证消息成功完成流操作了。如果宕机,这批数据就丢失了,无法保证At-Least语义。所以要通过checkpoint机制(Kafka数据同步1: Flink容错机制度)进行回放。
从系统中消费的某一时刻开始,看看checkpoint机制如何在FlinkKafkaConsumerBase中提供容错。
a. 提供输出流
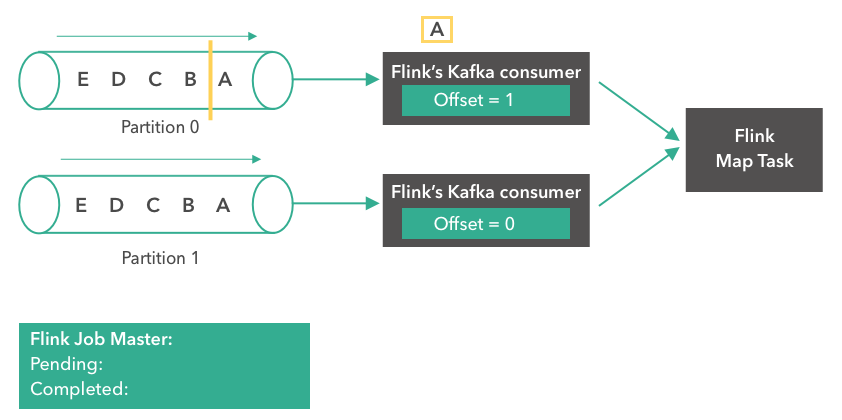
系统中的某一时刻,将数据输出。
b. 到达Barrier
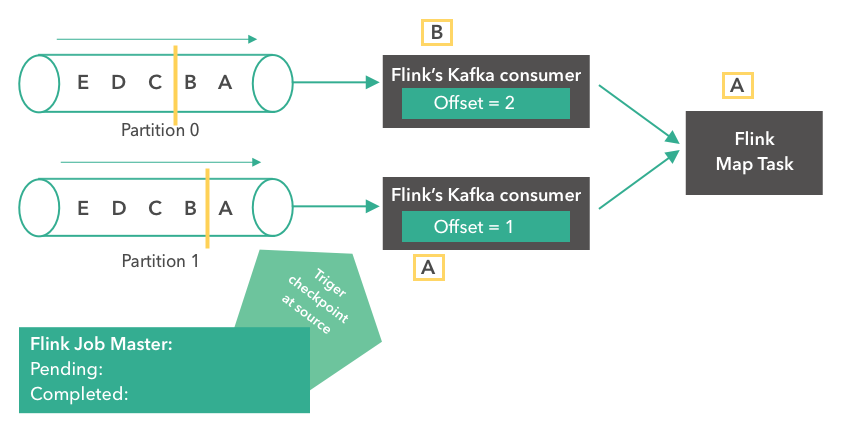
当读到 checkpoint barrier 边界时,会触发checkpointing操作产生系统快照,供后续出现故障重启时使用。
c. pre-commit: snapshotState
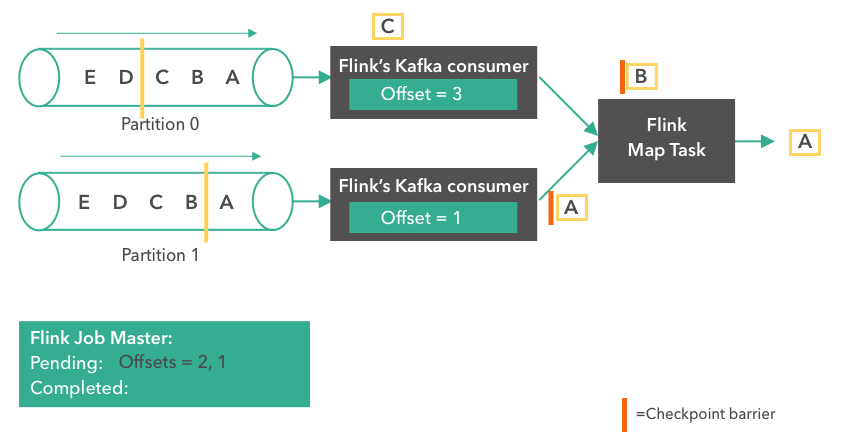
kafaConsumer将当前的offset保存到state。
//org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.java
//保存到state backend的offset数据
private transient ListState<Tuple2<KafkaTopicPartition, Long>> unionOffsetStates;
//pre-commit的offset数据
private final LinkedMap pendingOffsetsToCommit = new LinkedMap();
@Override
public final void snapshotState(FunctionSnapshotContext context) throws Exception {
// ...
unionOffsetStates.clear();
//更新state(重启task时使用)
for (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) {
unionOffsetStates.add(Tuple2.of(subscribedPartition.getKey(), subscribedPartition.getValue()));
}
// 保存pre-commit的offset数据(用于持久化保存,重启job时使用)
pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets);
// ......
}
d. commit: notifyCheckpointComplete
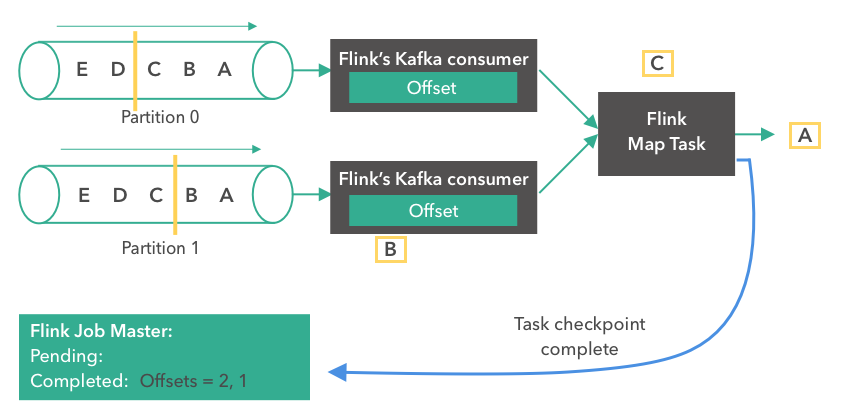
kafka consumer会提交offset,进入下一轮消费。job重启时,默认从本次提交的offset之后开始消费;如果task重启,先确保上一次的commit成功,再按照后面消费。
//org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.java
@Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
//获取当前checkpoint
final int posInMap = pendingOffsetsToCommit.indexOf(checkpointId);
//获取对应的偏移量
Map<KafkaTopicPartition, Long> offsets =
(Map<KafkaTopicPartition, Long>) pendingOffsetsToCommit.remove(posInMap);
// remove older checkpoints in map
for (int i = 0; i < posInMap; i++) {
pendingOffsetsToCommit.remove(0);
}
fetcher.commitInternalOffsetsToKafka(offsets, offsetCommitCallback);
}
e. initializeState任务重启
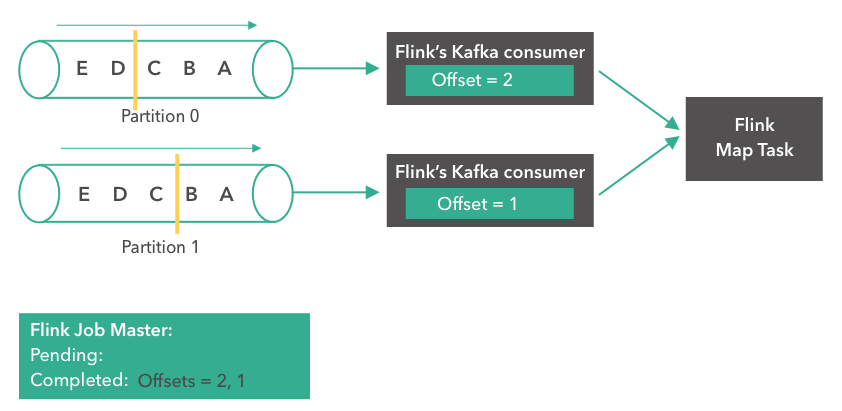
如果任务出错重启, 重启时会调用CheckpointedFunction的initializeState方法:
- 从状态中恢复事务信息
- 对pre-commit事务的提交
- 对失败的事务进行rollback。
需要commit的数据就是上一次checkpoint时保存在state中的offset。从该offset之后开始消费,就默认完成了事务的提交。
//org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.java
//1. state -> restoredState
@Override
public final void initializeState(FunctionInitializationContext context) throws Exception {
//从state backend获取state
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint<Tuple2<KafkaTopicPartition, Long>>() {})));
// 从state中获取上次checkpoint的偏移
for (Tuple2<KafkaTopicPartition, Long> kafkaOffset : unionOffsetStates.get()) {
restoredState.put(kafkaOffset.f0, kafkaOffset.f1);
}
}
//2. restoredState -> subscribedPartitionsToStartOffsets
@Override
public void open(Configuration configuration) throws Exception {
if (restoredState != null) {
for (KafkaTopicPartition partition : allPartitions) {
//如果恢复state不包含分区,设为EARLIEST_OFFSET
if (!restoredState.containsKey(partition)) {
restoredState.put(partition, KafkaTopicPartitionStateSentinel.EARLIEST_OFFSET);
}
}
//恢复offset
for (Map.Entry<KafkaTopicPartition, Long> restoredStateEntry : restoredState.entrySet()) {
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
}
// 3. subscribedPartitionsToStartOffsets开始消费
@Override
public void run(SourceContext<T> sourceContext) throws Exception {
//给fetch设置消费起始位移
this.kafkaFetcher = createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
periodicWatermarkAssigner,
punctuatedWatermarkAssigner,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
}
f. job重启(较少)
类似2PC成功执行的前提是Coordinator正常运行,Flink的2PC执行的前提也是Job Master正常运行。但是如果整个Flink应用突然宕机或者出现其他异常,我们被迫在新的Flink应用重启job。此时state消失了,自然也无法获取checkpoint数据了,如何将数据恢复到一致呢?
默认Job重启后,consumer会接着上次commit成功的offset开始消费,这样至少能保证 At-Least 语义。但是,如果要实现 exactly-once 语义,还需要更严格的要求(即保证外部存储的rollback)。