Kafka数据同步3: Kafka2Doris
1. Doris Label
Copy From: doris的label的理解
label 是用于表示一次导入操作的标识。在doris中,任何导入方式都会有一个label。这个label可以是用户指定的,也可能由系统自动生成。
label的目的是帮助实现 “At-Most” 的导入语义。即同一个label,在一个database内,只能被成功导入一次。如果一个label已经成功导入,如果再次使用这个label进行导入,会报错“Label already used”。而如果导入失败,则可以使用相同的label继续重试导入。
通过“At-Most”的导入语义,如果配合上游系统“At-Least”数据生产语义,则可以实现端到端的“Exactly-once”语义,保证数据不丢不重。
无法查看一个表里有哪些label,因为label对应的是导入任务,而不是表。
2. 设计思路
Kafka2Doris没有采用checkpoint机制来保证一致性,而是通过 Doris Label + offset来保证exact-once语义:
-
Flink先保存消费的Kafka消息到Batch,然后串行发送Batch数据到Doris。即每次发送一批数据前,上一批数据已经发送成功。
-
每次提交数据到Doris前,会保存如下信息到Zookeeper:Kafka分区offset范围[startOffset, EndOffset]和Doris Label。
-
每次重启job时,从Zookeeper中获取每个分区的上一次消费的分区范围和Label,然后查询label是否导入成功:
- 如果导入成功,说明上一次消费成功,offset = endOffset + 1
- 如果导入失败,说明上一次消费失败, offset = startOffset。
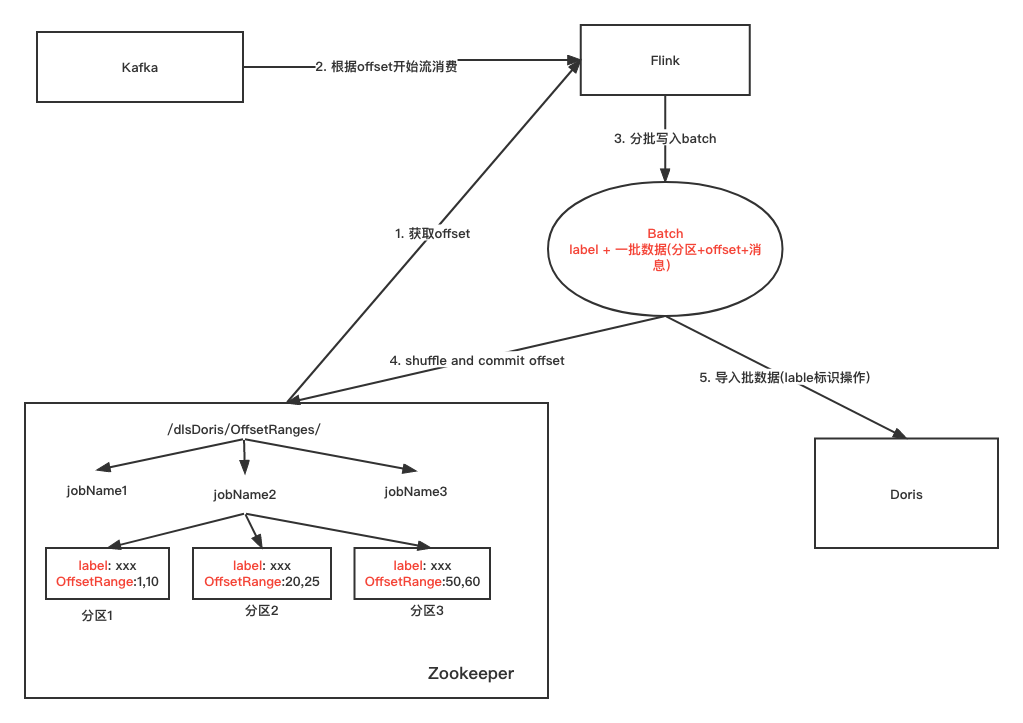
3. 详细流程
-
Job重启时先从Zookeeper中获取offset
-
启动Flink作业,DataSource从offset开始消费。
-
Sink会调用DorisWriter向PipelineManager写入消息(速度取决于DorisParser线程处理速度,漏桶式设计)
-
DorisParser采用parallelism个线程获取与解析Sink中的消息,然后放到Batch中批量发送。即当前Sink已经消费的消息 = Doris中已同步的消息 + Batch中的消息 + parallelism个Parser线程正在解析的消息
-
DorisSender以Batch为单位发送数据,先提交offset, 再发送数据(最多重试sendMaxRetry次)
